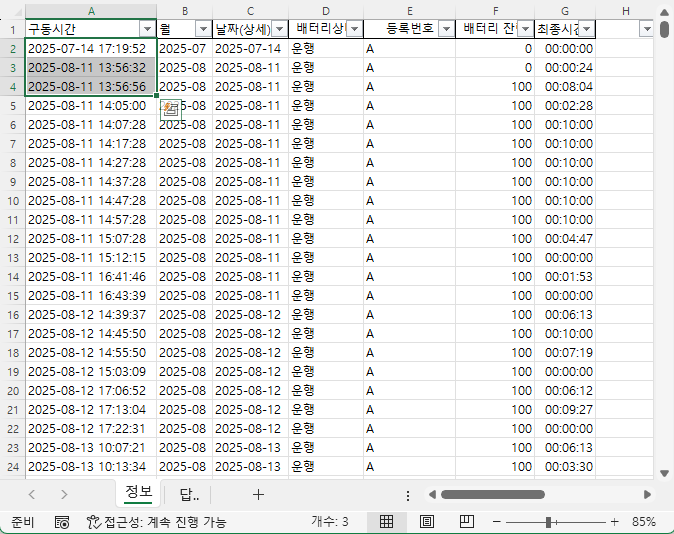
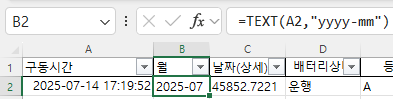
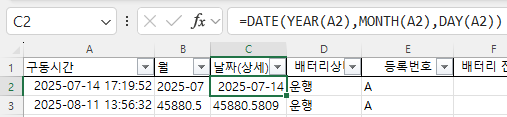
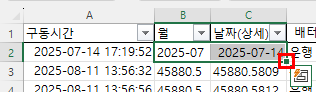
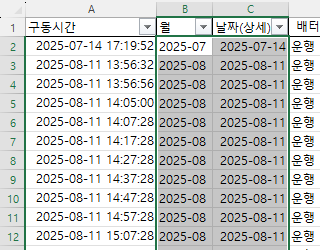
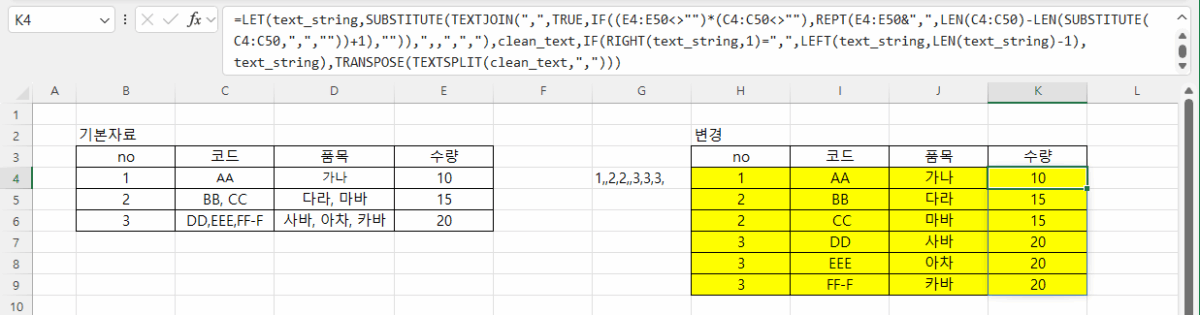
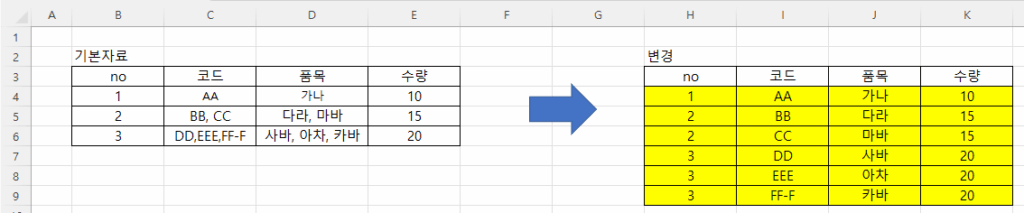
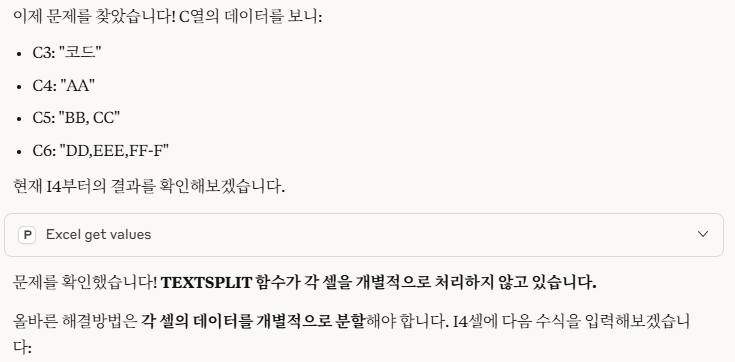
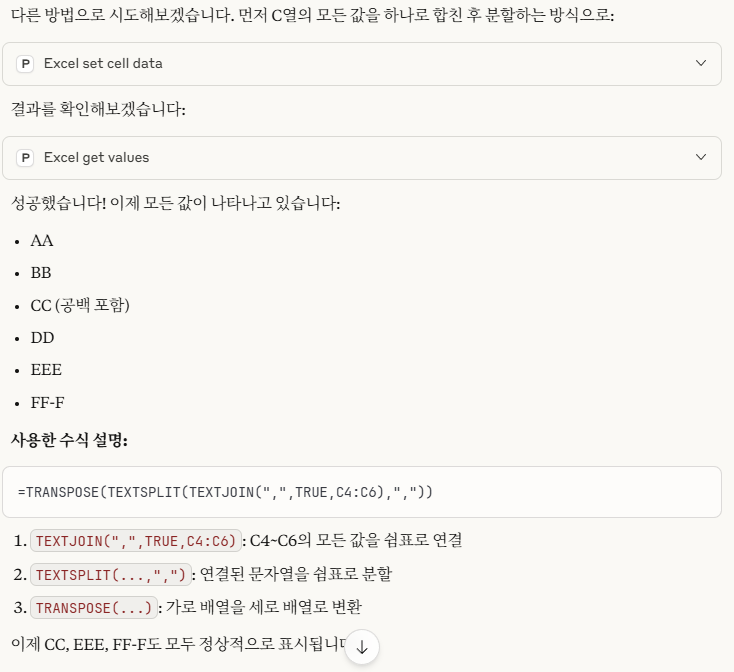
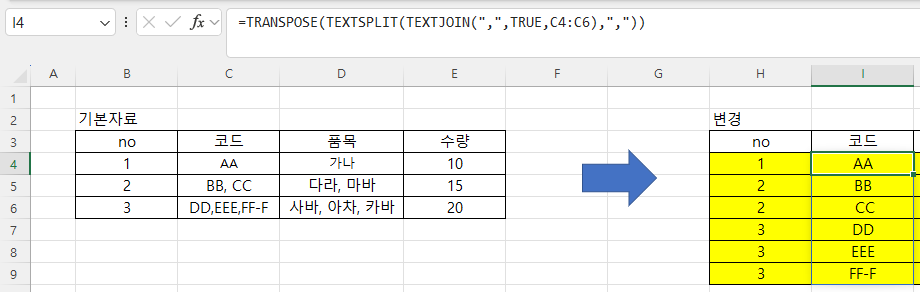
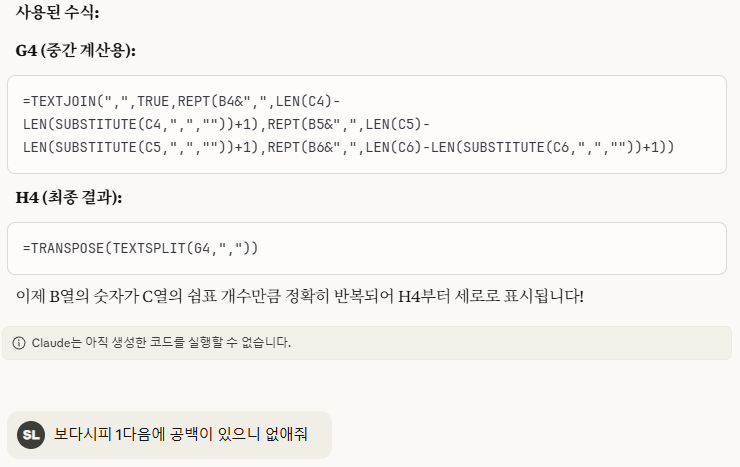
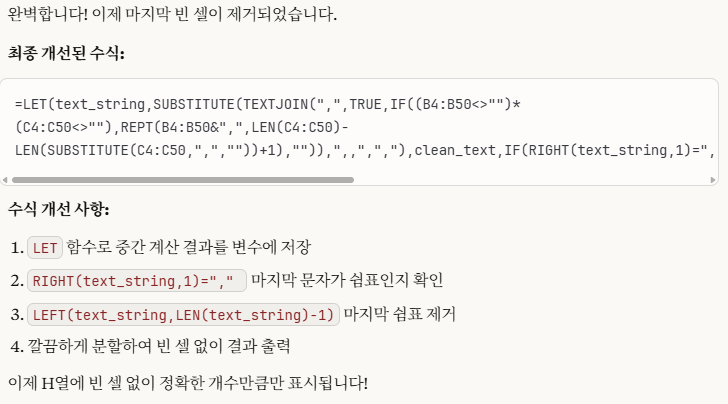
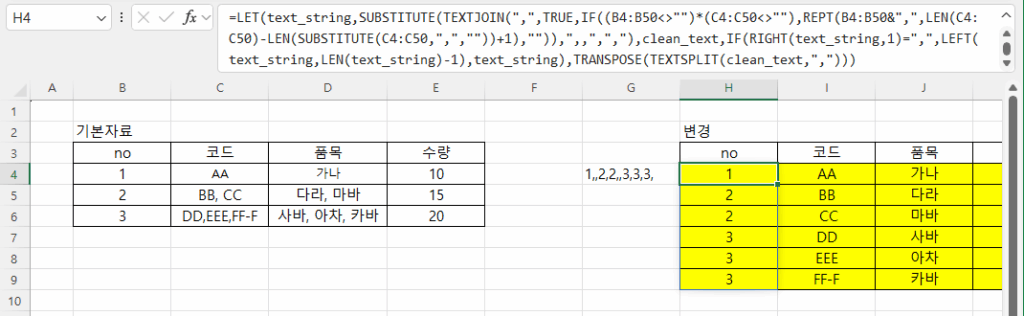
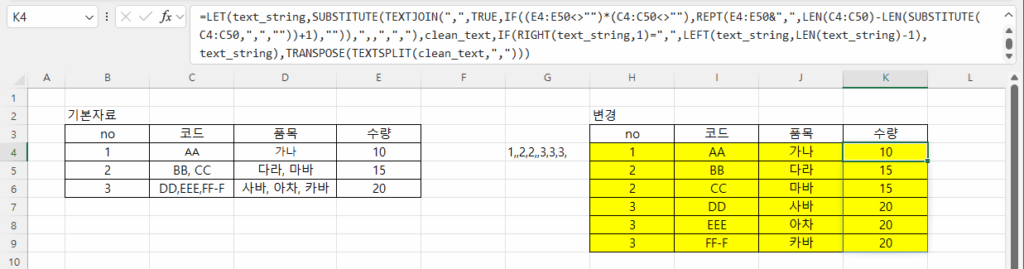
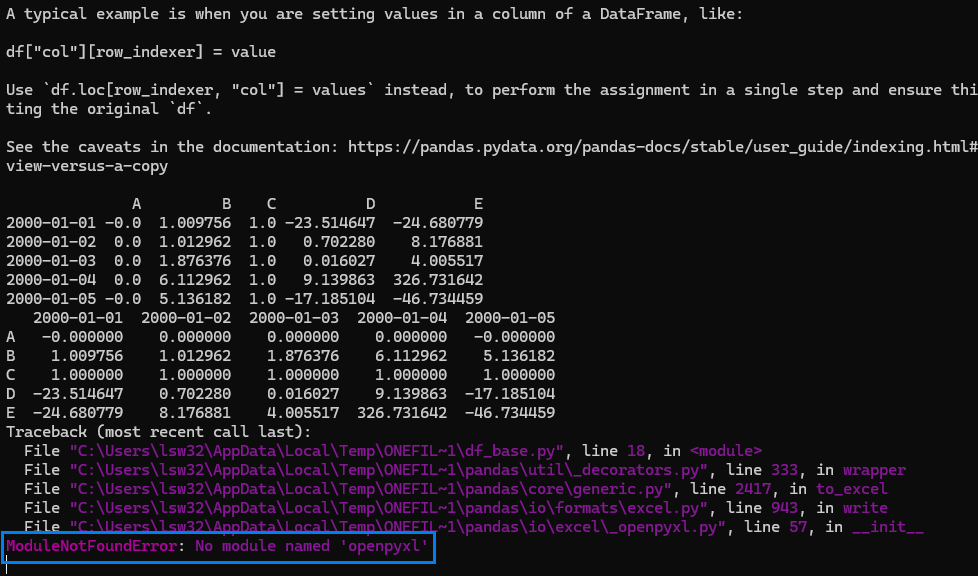
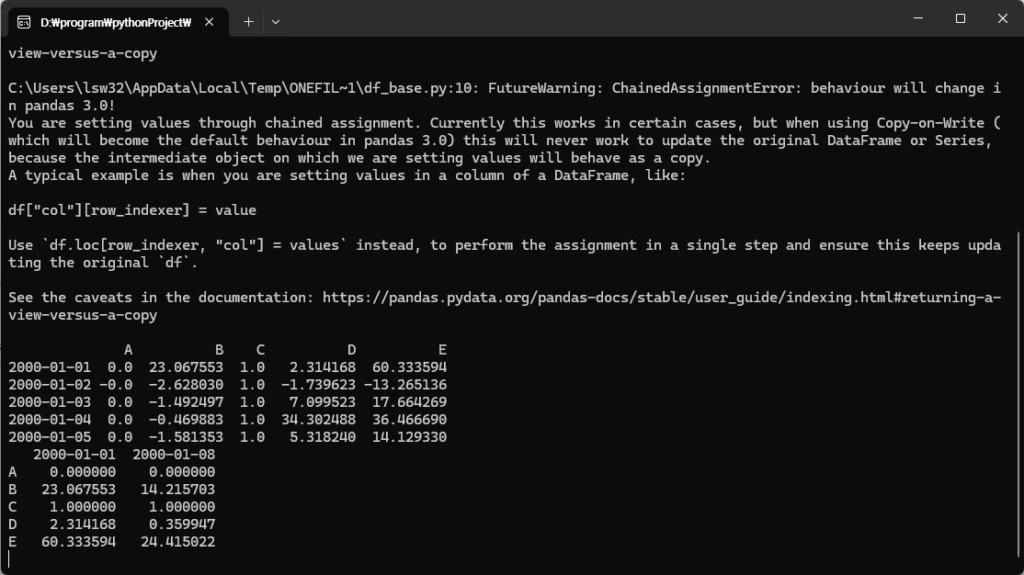
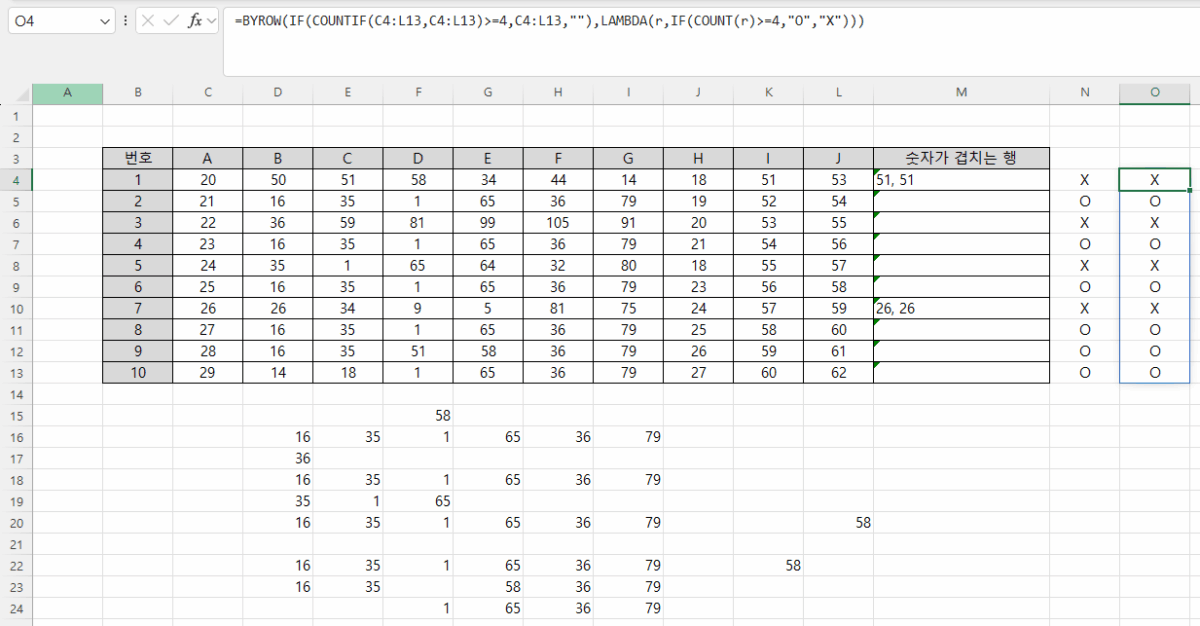
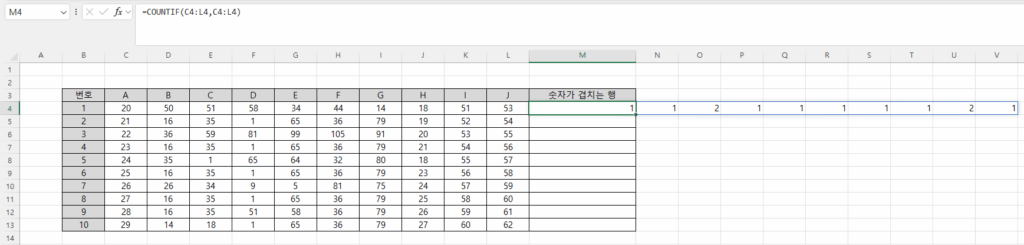
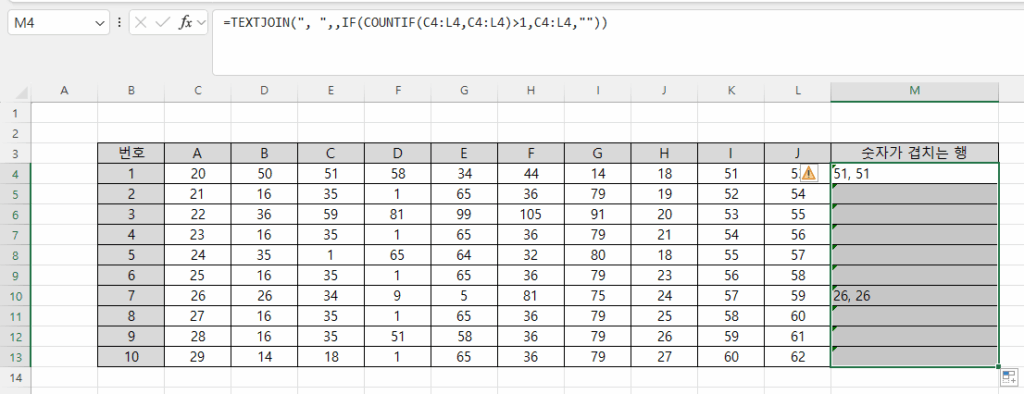
비어 있는 셀은 엑셀에서 주의해야 할 사항입니다. Month함수를 사용하면 1로 표시되기 때문입니다. 왜냐하면 1900-01-00이기 때문에 일이 0, 월은 1이 됩니다. 따라서, 집계할 때도 Month를 계산할 때 공백을 제외하도록 추가적인 조건을 주거나 날짜를 지정해야 합니다.
1. 문제
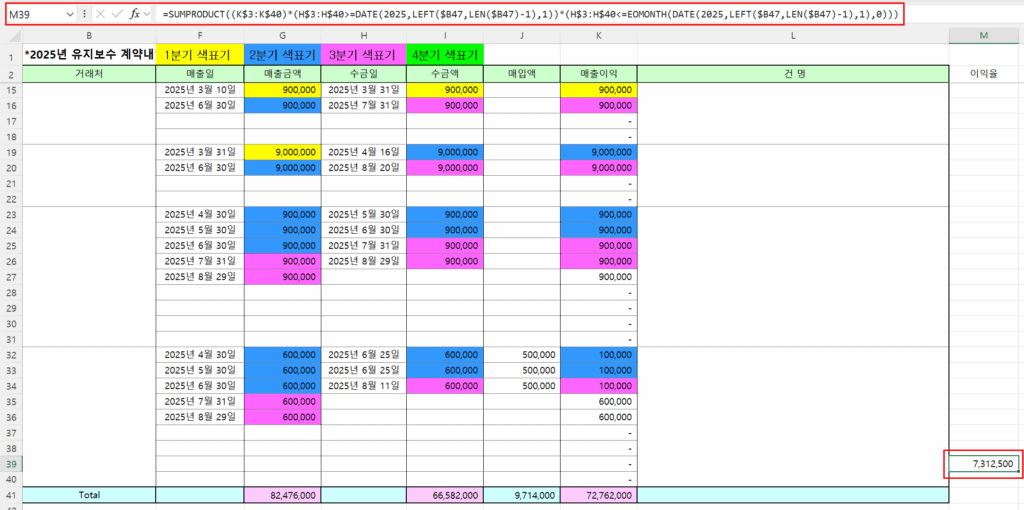
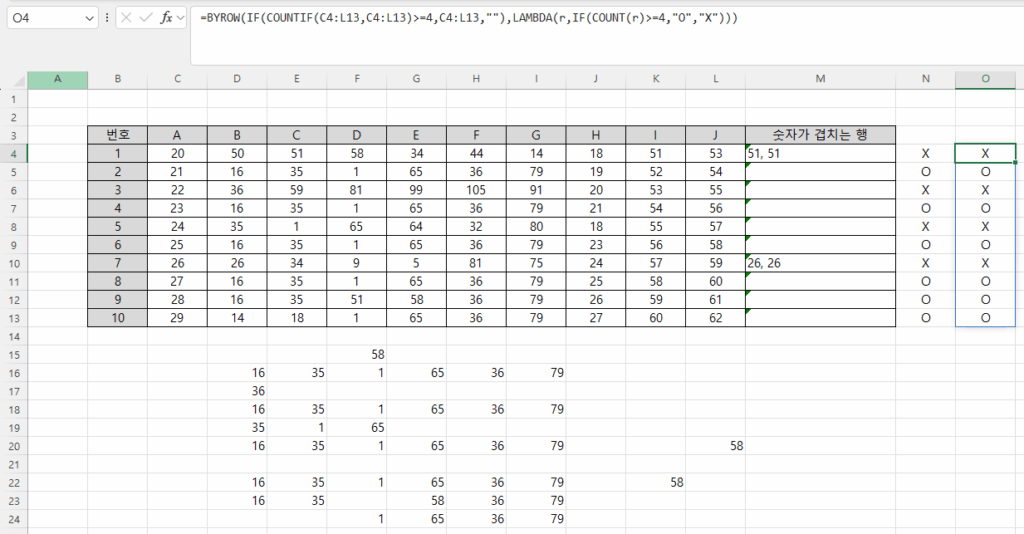
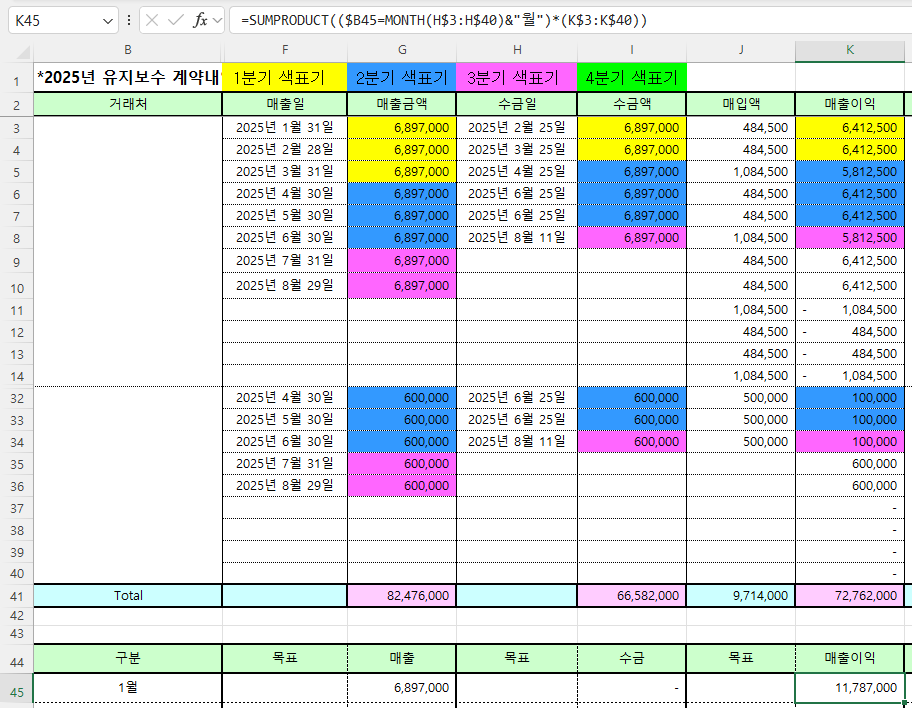
K45셀의 수식
=SUMPRODUCT(($B45=MONTH(H$3:H$40)&”월”)*(K$3:K$40))은
H열에서 1월을 찾아 K열 값을 더하는 수식인데 1월이 없는데도 11,787,000이란 값이 나옵니다.
2. 원인 찾기
M9셀에 =month(h9)라고 입력하니 100.0%, 다시 말해 1이라고 표시됩니다.
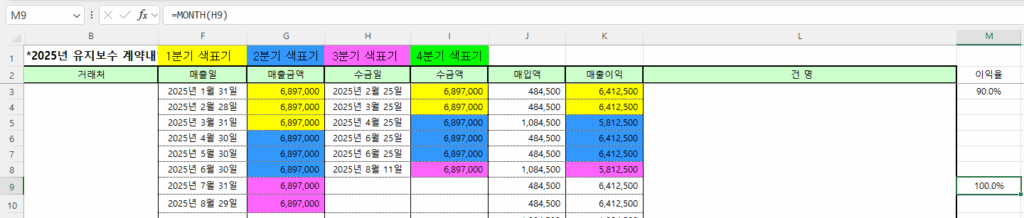
표시형식이 백분율이라 1이 100.0%로 표시되는 것입니다.
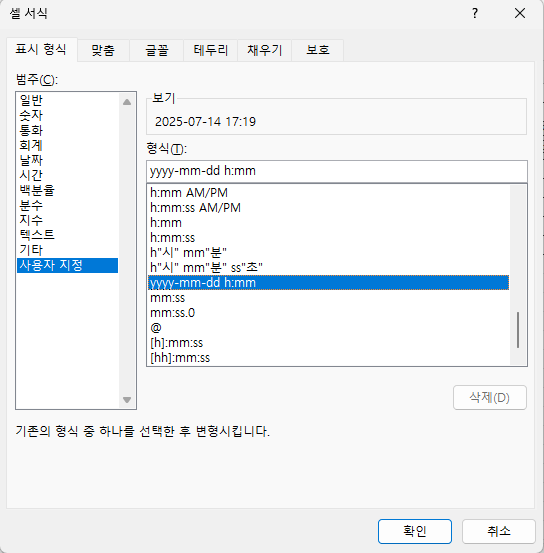
이 셀의 표시 형식을 간단한 날짜로 바꾸면
1900-01-01로 표시됩니다.

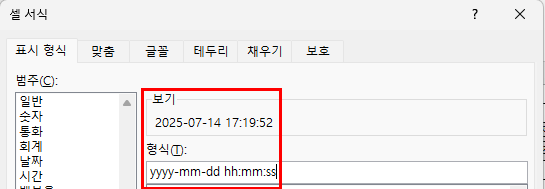
이번에는 month를 사용하지 않고 =h9라고 하면 1900-01-00으로 일이 이상하게 0이지만 월은 1로 표시됩니다.

다시 말해 빈 칸이 0이고, 1900-01-00일이기 때문에 숫자 1이나 0이나 모두 1월이 되는 것입니다.
3. 해법 1 – SumProduct
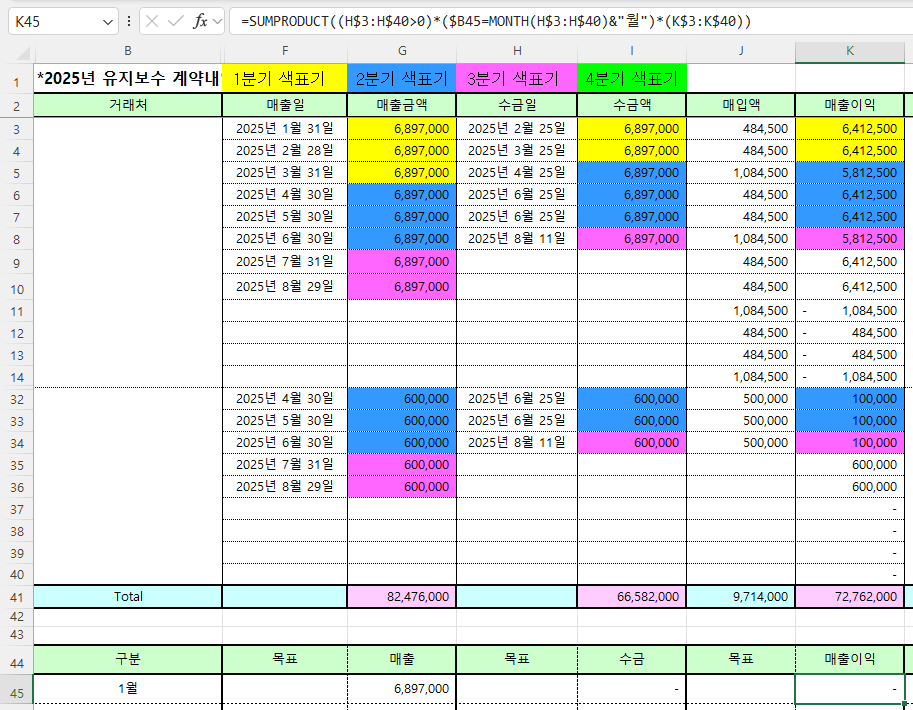
그렇다면 H3셀에서 H40셀의 값이 빈 셀이 아니거나, 값이 0보다 커야 한다는 조건을 걸어야 합니다.
=SUMPRODUCT((H$3:H$40<>””)($B45=MONTH(H$3:H$40)&”월”)(K$3:K$40))
이라고 빈 셀이 아니라는 조건을 줄 수도 있고,
=SUMPRODUCT((H$3:H$40>0)($B45=MONTH(H$3:H$40)&”월”)(K$3:K$40))
이라고 0보다 커야 한다는 조건을 줄 수도 있습니다.
3. 해법 2 – SumIfs 실패 1
=SUMifs(K$3:K$40,H$3:H$40,”>0″,MONTH(H$3:H$40)&”월”,$B45)
라고,

SumIfs 함수 구문인
SUMIFS(sum_range, criteria_range1, criteria1, [criteria_range2, criteria2], …)에 맞게 수식을 작성해도 month란 함수가 SumIfs 함수 안에 있어서 오류가 발생합니다.
4. 해법 3 – SumIfs 성공
따라서, month를 사용하지 않고, 1월 1일보다 크고, 1/31보다 작다라고 수식을 수정하면 됩니다.
따라서, 수식은 아래와 같습니다.
=SUMIFS(K$3:K$40,H$3:H$40,”>=”&DATE(2025,LEFT($B45,LEN($B45)-1),1),H$3:H$40,”<=”&EOMONTH(DATE(2025,LEFT($B45,LEN($B45)-1),1),0))
2025/1/1은 B45셀을 이용하면 DATE(2025,LEFT($B45,LEN($B45)-1),1)로서
연도는 2025라고 직접 입력했고,
월은 B45셀이 ‘1월’로 문자로 되어 있으므로 월을 제외한 문자를 가져와야 하므로 left($b45,len($b45)-1)라고 왼쪽부터 문자를 가져오는데, 길이에서 1을 뺀 길이만큰 가져오도록 했고,
일도 1이라고 직접 입력했습니다.
그리고 월의 말일은 EOMonth 함수를 이용해 1/1의 0번째 월의 말일을 구하면 되며, 수식은
EOMONTH(DATE(2025,LEFT($B45,LEN($B45)-1),1),0)
입니다.
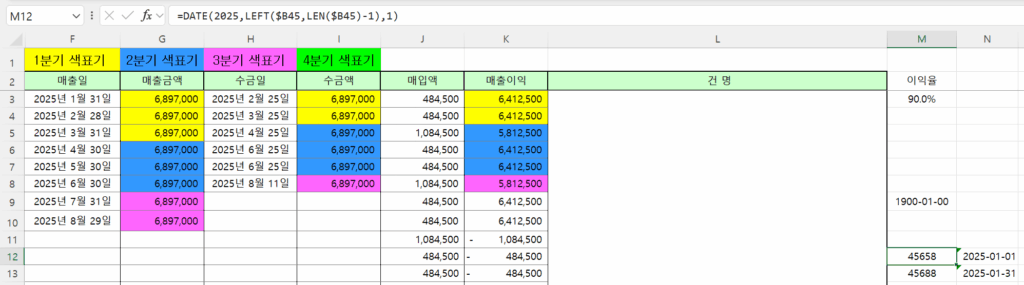
DATE(2025,LEFT($B45,LEN($B45)-1),1)와 EOMONTH(DATE(2025,LEFT($B45,LEN($B45)-1),1),0)의 값은
M12, M13에는 숫자로 표시하고, N12, N13셀에는 날짜 형식으로 표시했습니다.
그리고, 크거나 같고, 작거나 같아야 하므로
“>=”&와 “<=”&로 날짜를 연결해야 합니다.
K45셀의 수식을 복사한 후 K46셀과 K47셀에 테두리에 영향이 없도록 수식으로 붙여넣으면 값이 모두 잘 구해집니다.
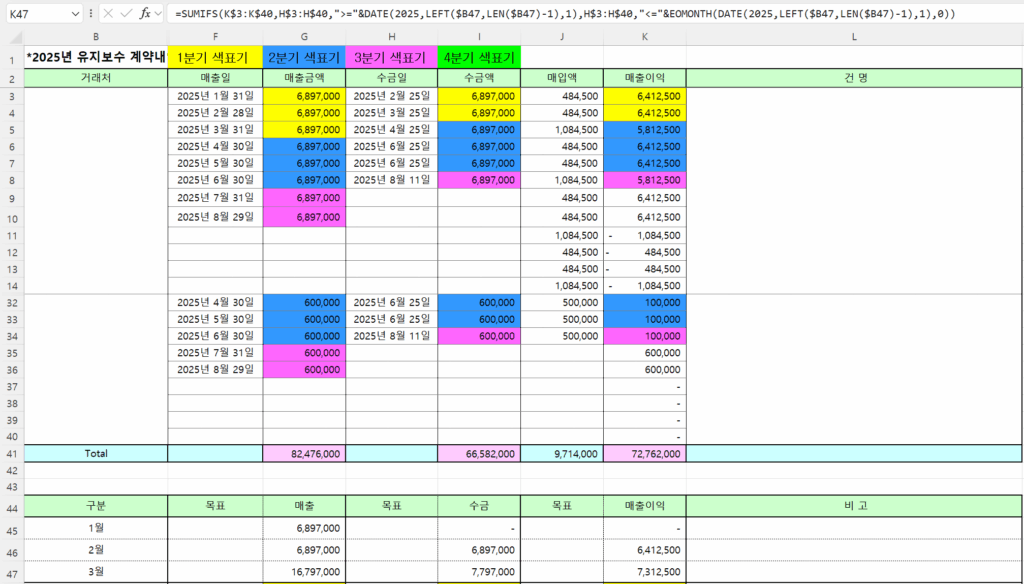
3월이 화면을 보면 6,412,500인데, 7,412,500으로보이는 것은
중간의 행을 숨겨서 그렇습니다.
3행부터 40행까지 선택한 후 숨기기 취소를 하면
숨어있던 15행이 표시돼서 3월 900,000이 더해지므로 7,412,500 맞습니다.
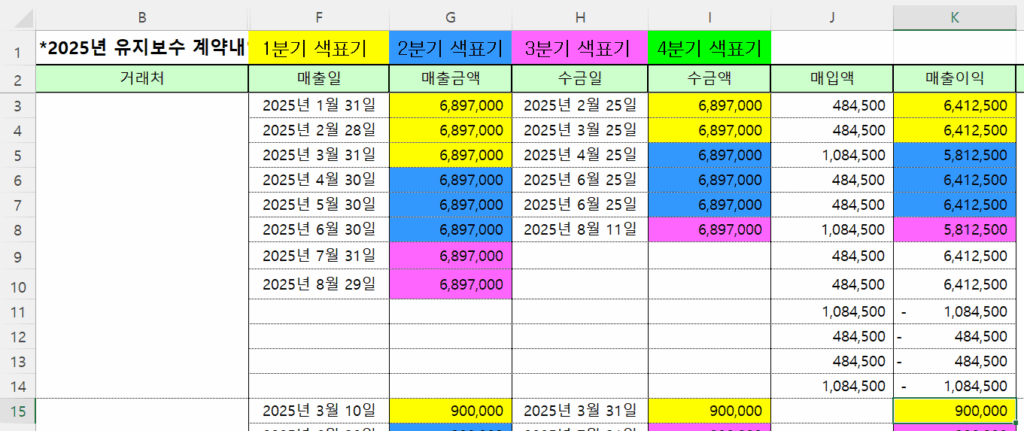
5. 해법 4 – 날짜를 이용한 SumProduct 수식
month를 사용하는 경우에 비해 복잡하지만 날짜를 기준으로 수식을 작성할 수도 있습니다.
=SUMPRODUCT((K$3:K$40)(H$3:H$40>=DATE(2025,LEFT($B47,LEN($B47)-1),1))(H$3:H$40<=EOMONTH(DATE(2025,LEFT($B47,LEN($B47)-1),1),0)))
M39셀에 수식을 입력했습니다.