Rust에서 variable binding(변수 바인딩)은 값을 변수 이름에 연결하는 과정을 의미하며, Rust 프로그래밍에서 변수 선언과 관련된 기본 개념입니다. Rust는 정적 타입 언어이고 기본적으로 변수가 불변(immutable)으로 선언되기에, 가변성을 가지려면 일부러 명시해야 합니다. 이와 함께 Rust의 바인딩은 shadowing(변수 가리기)이나 스코프와 밀접하게 연관되어 있어, 변수 활용 시 중요한 개념입니다.
Ⅰ. 기본 자료형(Primitive Type)
1. 변수 바인딩 기본
Rust에서 변수 바인딩은 let 키워드로 선언합니다. 이때 변수는 기본적으로 불변입니다. 따라서 선언 후 값을 변경하려 하면 컴파일 에러가 발생합니다.
fn main() {
let x = 5;
println!("x의 값: {}", x);
// x = 6; // 오류: 불변 변수에 재할당 불가
}
이 코드는 x를 5로 바인딩했지만, 이후 x = 6과 같이 변경하려 하면 컴파일 에러가 발생합니다. Rust 컴파일러는 이런 불변 변수 변경 시도를 막아 안정성을 보장합니다.
2. 가변 변수 (Mutable Binding)
변수를 변경 가능하게 하려면 mut 키워드를 사용해 가변 변수로 선언해야 합니다.
fn main() {
let mut x = 5;
println!("초기 x: {}", x);
x = 6;
println!("변경된 x: {}", x);
}
이렇게 하면 x에 대한 값 변경이 가능해집니다. 컴파일러가 에러 발생 시 mut를 추가하라고 친절히 안내하는 점도 Rust의 특징입니다.
3. 타입 추론 및 명시적 타입 선언
Rust 컴파일러는 대부분의 경우 변수 선언 시 타입을 자동 추론합니다.
let x = 42; // i32로 추론
let y = true; // bool로 추론
let z: u32 = 10; // 명시적 타입 선언
필요에 따라 타입을 명시할 수도 있지만, 대부분 타입 추론에 맡깁니다.
4. 변수 가리기 (Shadowing)
Rust의 독특한 특징인 변수 가리기는 같은 이름의 변수를 같은 스코프 내에서 다시 let으로 선언하여 새 변수를 만드는 것입니다. 이때 이전 변수는 새 변수에 의해 가려집니다.
fn main() {
let x = 5;
let x = x + 1; // 이전 x를 가리고 새 x 선언
{
let x = x * 2;
println!("내부 스코프의 x: {}", x); // 12
}
println!("외부 스코프의 x: {}", x); // 6
}
위 예제에서 첫 번째 x는 5, 두 번째는 6, 내부 스코프의 x는 12입니다. 이렇게 하면 가변 변수 없이도 값 변경 효과를 낼 수 있고 타입도 변경할 수 있습니다.
5. 스코프와 변수 유효 범위
변수는 선언된 블록 {} 내에서만 유효하며, 블록을 벗어나면 사라집니다.
fn main() {
let x = 1;
{
let y = 2;
println!("내부 스코프 y: {}", y); // 2
}
// println!("외부 스코프 y: {}", y); // 오류: y는 유효하지 않음
}
또한 내부 스코프에서 같은 이름으로 변수를 다시 선언하면 외부 변수를 가립니다.
6. 실습 예제 종합
fn main() {
// 불변 변수
let a = 10;
println!("a: {}", a);
// a = 20; // 컴파일 에러!
// 가변 변수
let mut b = 10;
println!("b 초기값: {}", b);
b = 20;
println!("b 변경 후: {}", b);
// 변수 가리기 (shadowing)
let c = 5;
let c = c + 10; // 이전 c 가리기, 이제 c = 15
println!("c: {}", c);
{
let c = c * 2; // 내부 스코프 가리기, c = 30
println!("내부 블록의 c: {}", c);
}
println!("외부 블록의 c: {}", c);
// 타입 변경이 가능한 shadowing
let d = "문자열";
println!("d는 문자열: {}", d);
let d = d.len(); // 같은 이름 변수에 정수 대입 (shadowing)
println!("d는 문자열 길이: {}", d);
}
출력 결과:
a: 10
b 초기값: 10
b 변경 후: 20
c: 15
내부 블록의 c: 30
외부 블록의 c: 15
d는 문자열: 문자열
d는 문자열 길이: 6
Ⅱ. 벡터(Vector)와 튜플(Tuple) 타입 변수 바인딩
1. 벡터(Vector) 타입 변수 바인딩
벡터는 같은 타입 요소들을 동적 크기로 저장하는 컬렉션입니다. Rust에서 벡터는 Vec<T> 타입으로 표현됩니다.
- 벡터 바인딩 기본 예:
fn main() {
// 빈 vector 생성 (타입 명시 필요)
let mut v: Vec<i32> = Vec::new();
// 값 추가 가능하려면 mut 필요
v.push(1);
v.push(2);
println!("{:?}", v); // 출력: [1, 2]
// 초기값과 함께 벡터 생성 (타입 추론 가능)
let v2 = vec![10, 20, 30];
println!("{:?}", v2); // 출력: [10, 20, 30]
}
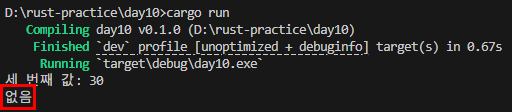
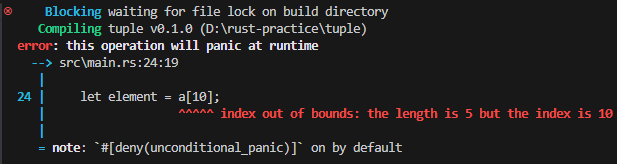
- 벡터의 요소 접근:
let first = v2[0]; // 인덱스를 통한 접근 (주의: 범위 초과 시 패닉)
let maybe_first = v2.get(0); // Option 타입 반환 (안전 접근)
- 가변 벡터 요소 수정도 mut으로 가능:
let mut v3 = vec![1, 2, 3];
v3[1] = 5; // 두 번째 요소를 5로 변경
벡터는 가변성을 가지고 가리키는 데이터가 동적으로 바뀔 수 있으므로 보통 mut 바인딩과 함께 선언합니다.
2. 3차원 벡터
1) 가변 크기: Vec<Vec<Vec<T>>>
// 2 x 3 x 4 크기의 0으로 채워진 3차원 벡터
let x = 2;
let y = 3;
let z = 4;
let mut v: Vec<Vec<Vec<i32>>> = vec![vec![vec![0; z]; y]; x];
// 읽기
let a = v[1][2][3];
// 쓰기
v[0][1][2] = 42;
헬퍼 함수를 하나 두면 더 편합니다:
fn new_3d<T: Clone>(x: usize, y: usize, z: usize, value: T) -> Vec<Vec<Vec<T>>> {
vec![vec![vec![value.clone(); z]; y]; x]
}
let mut v = new_3d(2, 3, 4, 0i32);
2) 고정 크기: 중첩 배열(스택 또는 Box로 힙에)
크기가 컴파일 타임에 고정되어 있다면 배열을 사용할 수 있습니다.
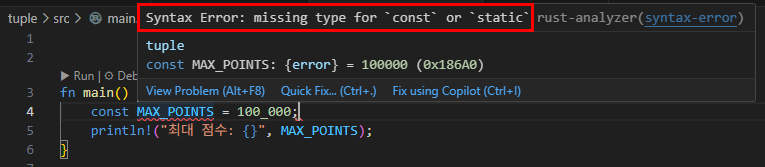
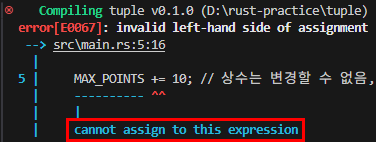
const X: usize = 2;
const Y: usize = 3;
const Z: usize = 4;
let mut v: [[[i32; Z]; Y]; X] = [[[0; Z]; Y]; X];
v[1][2][3] = 7;
크기가 커서 스택에 올리기 부담스럽다면 Box로 감싸 힙에 둘 수도있습니다.
let mut v: Box<[[[i32; Z]; Y]; X]> = Box::new([[[0; Z]; Y]; X]);
3) 평탄화(flat)한 1차원 Vec<T> + 인덱스 계산
성능/메모리 지역성을 위해 1차원 벡터에 직접 담고 인덱스를 수식으로 계산하는 패턴도 자주 씁니다.
struct Vec3D<T> {
data: Vec<T>,
x: usize,
y: usize,
z: usize,
}
impl<T: Clone> Vec3D<T> {
fn new(x: usize, y: usize, z: usize, value: T) -> Self {
Self {
data: vec![value; x * y * z],
x, y, z,
}
}
#[inline]
fn idx(&self, i: usize, j: usize, k: usize) -> usize {
// (i, j, k) -> linear index
i * self.y * self.z + j * self.z + k
}
fn get(&self, i: usize, j: usize, k: usize) -> &T {
&self.data[self.idx(i, j, k)]
}
fn get_mut(&mut self, i: usize, j: usize, k: usize) -> &mut T {
let idx = self.idx(i, j, k);
&mut self.data[idx]
}
}
let mut v = Vec3D::new(2, 3, 4, 0i32);
*v.get_mut(1, 2, 3) = 5;
2. 튜플(Tuple) 타입 변수 바인딩
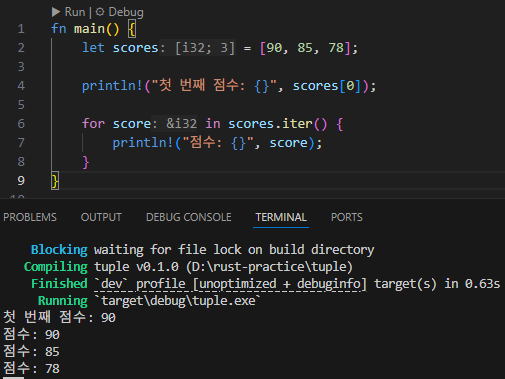
튜플은 여러 개의 서로 다른 타입 값을 하나로 묶는 복합 타입입니다. 고정 길이이며 각각 요소의 타입은 다를 수 있습니다.
- 튜플 선언과 바인딩:
let tup: (i32, f64, char) = (500, 6.4, 'z');
- 튜플의 요소에 접근하려면 패턴 매칭 또는 점(.) 표기법 사용:
let (x, y, z) = tup; // 구조 분해 (destructuring)
println!("x: {}, y: {}, z: {}", x, y, z);
let five_hundred = tup.0;
let six_point_four = tup.1;
let z_char = tup.2;
튜플은 기본적으로 불변이며, 가변 선언 시 요소 변경 가능:
let mut tup2 = (1, 2);
tup2.0 = 5; // 첫 번째 요소 변경 가능
4. 스코프와 바인딩의 변수 가리기
벡터, 튜플 등도 기본 자료형과 마찬가지로 스코프 내에서 변수 가리기(shadowing)가 가능합니다:
let v = vec![1];
let v = vec![2, 3]; // 이전 v 가려짐
println!("{:?}", v); // [2, 3]
Ⅲ. 배열
1. 1차원 배열 정의 방법
let arr = [1, 2, 3]; // 길이 3의 1차원 배열
2. 2차원 배열
let arr = [[1, 2, 3], [4, 5, 6]]; // 2x3 배열
3. 3차원 배열
let arr = [
[[1, 2], [3, 4]],
[[5, 6], [7, 8]],
];
Ⅳ. 해시맵
Rust에서 해시맵(HashMap)의 변수 바인딩도 기본적으로 let 키워드를 사용해 이름을 해시맵 값에 바인딩하는 방식으로 이루어집니다. 즉, 해시맵도 다른 변수처럼 데이터 구조 전체를 하나의 변수 이름에 연결하는 행위입니다.
- 해시맵을 선언할 때는 use std::collections::HashMap;를 임포트하고,
- 보통 HashMap::new()를 호출하여 빈 해시맵을 만들고,
- let mut를 붙여 가변 바인딩을 해야 해시맵에 키-값 쌍을 추가하거나 수정할 수 있습니다.
예를 들어:
use std::collections::HashMap;
fn main() {
// 가변 해시맵 바인딩
let mut scores = HashMap::new();
// 값 삽입
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
// 값 접근
let team_name = String::from("Blue");
let score = scores.get(&team_name).copied().unwrap_or(0);
println!("Blue 팀 점수: {}", score);
// 해시맵의 모든 키-값 쌍 출력
for (key, value) in &scores {
println!("{key}: {value}");
}
}
- 여기서 scores 변수에 해시맵 데이터 구조가 바인딩되었고,
- mut 키워드 때문에 값 삽입과 변경이 가능합니다.
- .insert() 메서드로 키-값 쌍을 추가하거나 갱신하며,
- .get() 메서드로 해당 키에 연관된 값을 읽을 수 있습니다.
요약하면, 해시맵도 배열, 벡터, 튜플, 구조체와 같이 Rust에서 변수 바인딩 개념이 동일하게 적용됩니다. let으로 이름을 데이터에 바인딩하고, 변경하려면 mut가 필수입니다. 해시맵은 키-값 쌍 컬렉션이라는 점에서 특수하지만, 바인딩이라는 개념 면에서는 일반 변수와 차이가 없습니다.
추가적으로 해시맵 내부에 구조체 같은 복합 데이터 타입을 저장해도, 변수 바인딩과 관련된 기본 원칙은 같습니다.
Ⅴ. 사용자 정의 타입
Rust에서 사용자 정의 타입(예: 구조체와 열거형)에 대한 변수 바인딩은 기본 타입이나 벡터, 튜플 등과 동일하게 let 키워드를 사용하여 값을 변수 이름에 연결하는 것을 의미합니다. 하지만 구조체와 열거형은 내부 필드나 variant에 데이터를 포함할 수 있어서, 변수 바인딩과 활용이 더 다양한 형태로 나타납니다.
아래에서 구조체와 열거형을 사용자 정의 타입의 변수 바인딩 예제로 구체적으로 설명합니다.
1. 구조체(Struct) 변수 바인딩 예제
// 구조체 정의
struct Point {
x: i32,
y: i32,
}
fn main() {
// 구조체 인스턴스를 생성하고 변수 p에 바인딩
let p = Point { x: 10, y: 20 };
// 구조체 필드에 접근
println!("x: {}, y: {}", p.x, p.y);
// 가변 바인딩 시 필드 값 변경 가능
let mut p_mut = Point { x: 5, y: 5 };
p_mut.x = 15;
println!("변경된 x: {}", p_mut.x);
// 구조체를 분해하여 필드 값을 각각 변수에 바인딩
let Point { x: a, y: b } = p;
println!("분해된 x: {}, y: {}", a, b);
}
- let p = Point { … };에서 p는 Point 타입 값에 변수 바인딩입니다.
- 패턴 매칭처럼 let Point { x: a, y: b } = p; 구문으로 구조체 필드를 변수 a, b에 바인딩할 수도 있습니다.
- mut 키워드로 가변 바인딩을 선언하면 구조체 필드를 수정할 수 있습니다.
2. 열거형(Enum) 변수 바인딩 예제
// 열거형 정의
enum Message {
Quit, // 데이터 없는 variant
Move { x: i32, y: i32 }, // 필드가 있는 variant (struct-like)
Write(String), // 튜플 형태 variant
ChangeColor(i32, i32, i32), // 여러 필드를 가진 튜플 variant
}
fn main() {
// enum 값에 변수 바인딩
let msg = Message::Move { x: 10, y: 20 };
// match로 variant별 데이터 바인딩과 처리
match msg {
Message::Quit => println!("Quit variant"),
Message::Move { x, y } => println!("Move to x: {}, y: {}", x, y),
Message::Write(text) => println!("Write message: {}", text),
Message::ChangeColor(r, g, b) => println!("Change color to {}, {}, {}", r, g, b),
}
}
- let msg = Message::Move { x: 10, y: 20 };에서 msg가 Message enum의 Move variant 값에 바인딩되었습니다.
- match 문에서는 각 variant의 내부 데이터를 별도의 변수(x, y, text, r, g, b)에 패턴 매칭을 사용한 변수 바인딩으로 추출합니다.
- 열거형 값 하나가 여러 variant 중 하나로만 존재할 수 있기에, match를 통해안전하게 처리합니다.
요약
| 구분 | 변수 바인딩 방식 | 설명 |
|---|---|---|
| 기본 타입 | let x = 5; | 변수 이름이 단순 값과 바인딩됨 |
| 구조체 | let p = Point { … }; | 변수 이름이 구조체 인스턴스에 바인딩 |
| let Point { x: a, y: b } = p; | 구조체 필드를 변수에 분해하여 바인딩 | |
| 열거형 | let msg = Message::Write(“Hi”.to_string()); | 변수에 enum variant 값 바인딩 |
| match msg { Message::Write(text) => { … } } | match 내 패턴 매칭으로 variant 내 데이터에 변수 바인딩 |
이처럼 사용자 정의 타입에서도 변수 바인딩은 let을 사용해 값을 변수 이름에 연결하는 동일한 개념이며, 구조체는 필드별 분해 바인딩이 가능하고, 열거형은 variant별 패턴 매칭을 통해 내부 데이터를 변수에 바인딩하는 방식으로 동작합니다.