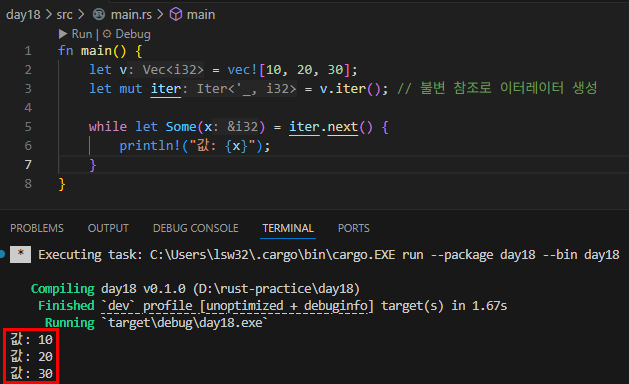
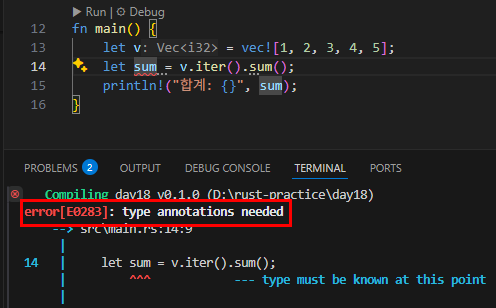
아래 코드의 핵심은 Iterator 트레이트의 연관 타입(associated type) 과 트레이트 구현에 의한 타입 유추입니다. Item이 직접적으로 코드 안에서 보이지 않지만, 트레이트 시스템이 자동으로 Iterator trait의 type Item과 연결해 주고 있습니다.
1. 예제 코드
struct GivesOne;
impl Iterator for GivesOne {
type Item = i32;
fn next(&mut self) -> Option<i32> {
Some(1)
}
}
fn main() {
let five_ones = GivesOne.into_iter().take(5).collect::<Vec<i32>>();
println!("{five_ones:?}");
}
2. 구조체 정의
struct GivesOne;
GivesOne은 단순한 빈 구조체입니다.
3.Iterator 트레이트 구현
impl Iterator for GivesOne {
type Item = i32;
fn next(&mut self) -> Option<i32> {
Some(1)
}
}
여기서 중요한 부분이 바로 type Item = i32; 입니다. Iterator 트레이트는 아래와 같이 정의되어 있습니다 (표준 라이브러리 축약본).
use aggregator::summarize;
fn main() {
let text = "Rust makes systems programming fun and safe!";
let summary = summarize(text);
println!("{}", summary);
}
7. Build and run
From the workspace root:
cargo run -p aggregator_app
Output:
Summary: Rust makes systems programming fun and safe!
✅ Now you have:
aggregator → library crate
aggregator_app → binary crate
managed together in one workspace.
Ⅱ. How to Test the Library
Let’s extend the workspace so you can test your aggregator library while also running the app. There are two ways to test library, one is adding tests inside the library and the other is adding separate integration tests in a tests/ directory
1. Add tests inside the library
Edit aggregator/src/lib.rs:
/// Summarize a given text by prefixing it.
pub fn summarize(text: &str) -> String {
format!("Summary: {}", text)
}
// Unit tests go in a special `tests` module.
#[cfg(test)]
mod tests {
// Bring outer functions into scope
use super::*;
#[test]
fn test_summarize_simple() {
let text = "Hello Rust";
let result = summarize(text);
assert_eq!(result, "Summary: Hello Rust");
}
#[test]
fn test_summarize_empty() {
let text = "";
let result = summarize(text);
assert_eq!(result, "Summary: ");
}
}
2. Run the tests
From the workspace root:
cargo test -p aggregator
Output (example):
running 2 tests
test tests::test_summarize_simple ... ok
test tests::test_summarize_empty ... ok
test result: ok. 2 passed; 0 failed
3. Run the app
From the same root:
cargo run -p aggregator_app
Output:
Summary: Rust makes systems programming fun and safe!
4. (Optional) Integration tests
You can also add separate integration tests in a tests/ directory inside the aggregator crate:
use aggregator::summarize;
#[test]
fn integration_summary() {
let text = "Integration testing is easy!";
let result = summarize(text);
assert_eq!(result, "Summary: Integration testing is easy!");
}
Run all tests in the workspace:
cargo test
✅ Now you have:
Unit tests inside src/lib.rs
Integration tests in tests/
Ability to run tests and app from the same workspace.
자바(Java)는 모든 메소드를 클래스 내부에 정의합니다. 그러나, 러스트(Rust)는 데이터 구조(Struct)와 메소드(Impl block)가 물리적으로 분리되어 있습니다. 구조체 안에는 데이터만 정의하고, 별도의 impl 블록에서 그 구조체에 대한 메소드를 구현합니다.
Ⅰ. 데이터 구조, 메소드 구현 방식 비교
1. 자바: 클래스 내부에 메소드
자바(Java)는 모든 메소드를 클래스 내부에 정의합니다. 이는 객체 지향 프로그래밍(OOP)의 특징으로, 데이터(필드)와 행동(메소드)이 하나의 단위(클래스)에 밀접하게 결합(cohesion)되어 있습니다.
2. 러스트: 구조체와 메소드의 분리
러스트(Rust)에서는 데이터 구조(Struct)와 메소드(Impl block)가 물리적으로 분리되어 있습니다. 구조체 안에는 데이터만 정의하고, 별도의 impl 블록에서 그 구조체에 대한 메소드를 구현합니다.
3. 장단점
구분
자바(메소드=클래스 내부)
러스트(메소드=구조체 외부)
응집성
데이터와 행동이 하나에 묶임
데이터와 행동이 분리되어 명확
확장성
상속 등 OOP 구조 확장 용이
Trait, 여러 impl로 유연하게 확장
가독성
클래스 안에서 한 번에 파악 가능
데이터 정의와 메소드 구현 분리
유연성
하나의 클래스가 하나의 메소드 집합
같은 구조체에 여러 impl, trait 구현 가능
재사용성
상속, 인터페이스로 구현
Trait 등으로 다양한 방식의 재사용
관리의 용이성
대형 클래스에서 복잡해질 수 있음
관련 없는 메소드를 구조체와 별도 구현 가능
코드 조직화
OOP 방식(클래스-중심)
데이터 중심(struct), 행동 분리(impl, trait)
자바는 객체 중심의 응집력, 개발 및 이해 용이성이 강점이나, 큰 클래스가 복잡해지거나 상속 구조의 한계 등이 있습니다.
러스트는 데이터와 행동의 분리로 역할이 명확하며, trait 기반의 확장성과 안전성이 강점이지만, 초보자에겐 코드 연관성 파악이 다소 불편할 수 있습니다.
Ⅱ. 예제를 통한 비교
1. 자바(Java)
자바에서는 데이터(필드)와 메소드가 한 클래스 내부에 정의되어 객체 지향 프로그래밍 패러다임에 맞춰 응집되어 있습니다.
public class Point { private int x; private int y;
// 생성자 public Point(int x, int y) { this.x = x; this.y = y; }
// 메소드: 두 점 사이 거리 계산 public double distance(Point other) { int dx = this.x - other.x; int dy = this.y - other.y; return Math.sqrt(dx * dx + dy * dy); }
// getter 메소드 public int getX() { return x; } public int getY() { return y; } }
// 사용 public class Main { public static void main(String[] args) { Point p1 = new Point(0, 0); Point p2 = new Point(3, 4); System.out.println(p1.distance(p2)); // 출력: 5.0 } }
특징: Point 클래스 내부에 데이터(x, y)와 동작(거리 계산 메소드)을 모두 포함.
장점: 객체 지향적 응집성(cohesion) 강화, 한 곳에서 모든 관련 기능 파악 가능.
단점: 클래스가 커질수록 복잡성 증가, 상속 구조 제한 등.
2. 러스트(Rust)
러스트는 데이터 구조체(struct)와 메소드 구현부(impl 블록)를 분리해서 작성합니다. 이로써 역할 분리가 명확해지고, 여러 impl 블록과 trait을 통해 유연하게 확장할 수 있습니다.
// 데이터 정의: 구조체는 필드만 가짐 struct Point { x: i32, y: i32, }
// 메소드 구현: impl 블록에서 정의 impl Point { // 연관 함수(정적 메서드와 유사) fn new(x: i32, y: i32) -> Point { Point { x, y } }
// 메소드: 두 점 사이 거리 계산 fn distance(&self, other: &Point) -> f64 { let dx = (self.x - other.x) as f64; let dy = (self.y - other.y) as f64; (dx.powi(2) + dy.powi(2)).sqrt() } }
fn main() { let p1 = Point::new(0, 0); let p2 = Point::new(3, 4); println!("{}", p1.distance(&p2)); // 출력: 5.0 }
특징: struct는 데이터만 선언, 메소드는 별도의 impl 블록에서 구현.
장점: 데이터와 행동이 분리되어 역할 명확, 여러 impl이나 trait로 기능 확장 유리, 컴파일타임 안전성 증대.
단점: 관련 데이터와 메소드가 코드상 분리되어 있어 한눈에 파악하기 어려울 수 있음, 전통적인 OOP 방식과 차이 있음.
3. 비교 표
항목
자바(Java)
러스트(Rust)
구조
클래스 내부에 데이터와 메소드가 함께 있음
구조체(데이터)와 impl 블록(메소드)로 분리
작성 방식
한 클래스 파일 내에서 모든 정의
struct로 데이터 정의, 별도 impl로 메소드 구현
확장성
상속과 인터페이스 기반 확장 (단일 상속)
여러 impl 블록과 trait 조합으로 유연하고 다중 확장 가능
가독성
관련 데이터와 메소드가 한 곳에 있어 파악 용이
데이터와 메소드가 분리되어 코드가 흩어질 수 있음
안전성
런타임 검사 및 가비지 컬렉션
컴파일 타임 소유권 및 빌림 검사로 메모리 안전성 강화
메모리
참조 타입 중심, 힙 할당 및 가비지 컬렉션 필요
값 타입 중심, 명확한 메모리 제어 및 성능 최적화 가능
객체 지향
전통적인 OOP 완전 지원
클래스는 없으나 trait로 인터페이스 역할 및 객체지향 유사 기능 제공
러스트의 구조체+impl 방식은 자바와는 다르게 데이터와 메소드가 분리되어 있지만, impl 블록 내에서 메소드를 묶어 객체 지향적 프로그래밍의 많은 특징을 흉내 낼 수 있습니다. trait를 활용하면 인터페이스 역할도 하며, 상속 대신 다중 trait 구현으로 유연하게 기능을 확장할 수 있습니다.
Ⅲ . 자바의 상속과 인터페이스 구조와 러스트의 고급 Trait(트레이트) 및 패턴 비교
자바의 상속과 인터페이스 구조와 러스트의 고급 Trait(트레이트) 및 패턴을 심도 있게 비교 설명하면 다음과 같습니다.
1. 자바의 상속과 인터페이스 구조
가. 상속 (Inheritance)
클래스 간에 “is-a” 관계를 표현하는 가장 기본적인 메커니즘입니다.
한 클래스가 다른 클래스(부모 클래스)를 상속받아 멤버 변수와 메소드를 재사용하거나 오버라이드할 수 있습니다.
단일 상속만 지원하여 다중 상속의 복잡성을 회피합니다.
상속 구조가 깊어지면 유지보수가 어려워지고, 부모 클래스 변경 시 자식 클래스에 의도치 않은 영향이 발생할 수 있음.
나. 인터페이스 (Interface)
여러 클래스가 구현해야 하는 메소드의 명세(계약)를 정의합니다.
자바 8부터는 디폴트 메소드 구현도 지원하여 일부 기능적 확장 가능.
인터페이스의 다중 구현이 가능해 상속 단점을 보완하고 다형성 제공.
인터페이스는 구현 메소드가 없거나 기본 구현만 제공하므로, 설계 시 유연성을 줌.
interface Flyer { void fly(); } class Bird implements Flyer { public void fly() { System.out.println("Bird is flying"); } } class Airplane implements Flyer { public void fly() { System.out.println("Airplane is flying"); } }
2. 러스트의 고급 Trait 및 패턴
가. Trait(트레이트) 개념
러스트의 트레이트는 특정 기능을 구현하도록 강제하는 인터페이스 역할을 합니다.
타입에 따라 여러 트레이트를 다중으로 구현할 수 있어 매우 유연합니다.
트레이트 내에 메소드 기본 구현(default method)을 제공해 부분 구현도 가능.
Trait는 다중 상속을 대체하며, 조합(composition) 및 다형성을 지원합니다.
나. 고급 트레이트 특징
(1) 동일 메소드명을 가진 다중 트레이트 구현 (충돌 해결)
예를 들어, 같은 이름 fly() 메소드를 가진 서로 다른 트레이트 Pilot, Wizard를 Human 타입에 모두 구현 가능.
호출 시 Pilot::fly(&human), Wizard::fly(&human)처럼 트레이트 이름을 명시해 충돌 해결.
fn main() { let person = Human; Pilot::fly(&person); // This is your captain speaking. Wizard::fly(&person); // Up! person.fly(); // *waving arms furiously* }
(2) 슈퍼 트레이트 (Super-traits)
한 트레이트가 다른 트레이트의 구현을 전제로 하는 경우 사용.
예: OutlinePrint 트레이트가 Display 트레이트를 반드시 구현한 경우에만 구현 가능하도록 제한.
use std::fmt::Display;
trait OutlinePrint: Display { fn outline_print(&self) { // Display 기능 이용해 출력하는 구현 println!("*{}*", self); } }
(3) 제네릭과 트레이트 바운드 (Trait Bounds)
함수, 구조체, 열거형 등에서 트레이트를 타입 매개변수 조건으로 지정하여 유연한 재사용성 제공.
Rust는 코드의 재사용성과 타입 안전성을 동시에 보장하기 위해 제네릭(Generic)과 트레잇(Trait)을 사용합니다. 이 개념은 Rust의 함수, 구조체, 열거형 등 다양한 곳에 적용되는데, 제네릭은 일반화된 타입을 의미하고, Trait은 공통된 행위 또는 특성을 의미합니다.
1. 제네릭(Generic)
가. 형식별 별도 함수
제네릭은 “특정 타입에 얽매이지 않고 다양한 타입에 대해 작동할 수 있도록 하는 일반화된 타입”을 의미합니다. 따라서, 타입에 의존하지 않는 유연한 코드를 작성할 수 있도록 도와줍니다.
아래 코드는 정수 타입 i32에 대해서는 largest_i32 함수를 사용하고, char에 대해서는 largest_char 함수를 따로 적용하고 있습니다.
fn largest_i32(list: &[i32]) -> i32 {
let mut largest = list[0];
for &item in list.iter() {
if item > largest {
largest = item;
}
}
largest
}
fn largest_char(list: &[char]) -> char {
let mut largest = list[0];
for &item in list.iter() {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let numbers = vec![34, 50, 25, 100, 65];
let result = largest_i32(&numbers);
println!("The largest number is {}", result);
let chars = vec!['y', 'm', 'a', 'q'];
let result = largest_char(&chars);
println!("The largest char is {}", result);
}
위 코드를 실행하면 아래와 같이 “가장 큰 수는 100, 가장 큰 문자는 y(번역)”라고 화면에 표시됩니다.
나. 제네릭 타입의 하나의 함수
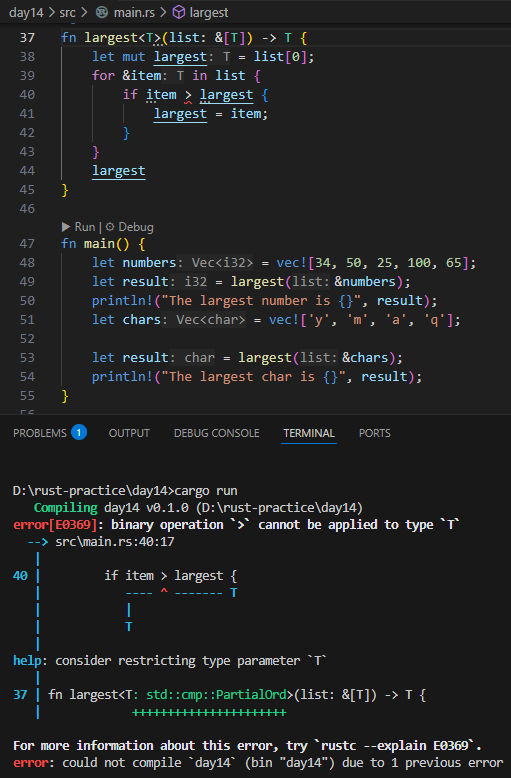
위와 같이 i32와 char라는 데이터 타입에 따라 다른 함수를 하나의 함수로 합치기 위해 T라는 제네릭을 이용했습니다.
fn largest<T: PartialOrd + Copy>(list: &[T]) -> T {
let mut largest = list[0];
for &item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let numbers = vec![34, 50, 25, 100, 65];
let result = largest(&numbers);
println!("The largest number is {}", result);
let chars = vec!['y', 'm', 'a', 'q'];
let result = largest(&chars);
println!("The largest char is {}", result);
}
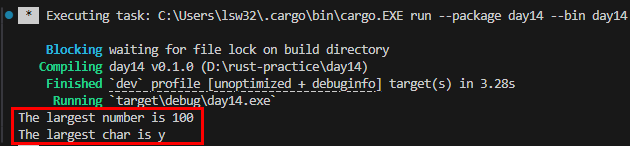
위 코드를 실행하면 The largest number is 100 The largest char is y 가 화면에 출력되는데,
Generic T를 정의하는 구문에서 : PartialOrd + Copy를 제거하고 실행하면
error[E0369]: binary operation > cannot be applied to type T (에러 E0369: 이진 동작인 > 는 T 타입에 적용될 수 없습니다) 란 에러 메시지가 표시되고,
그 아래 T 다음에 “: std:cmp::PartialOrd를 추가하라고 합니다.
PartialOrd는 두 값을 비교하여 크거나 작거나 같은지 부분적으로만 결정할 수 있는 경우를 위해 설계되었습니다. 예를 들어 부동 소수점 숫자(floating-point numbers)의 경우 NaN (Not a Number) 값이 존재하기 때문에 완전한 비교가 불가능합니다. Ord는 두 값을 항상 비교할 수 있는 경우를 위해 설계되었습니다.
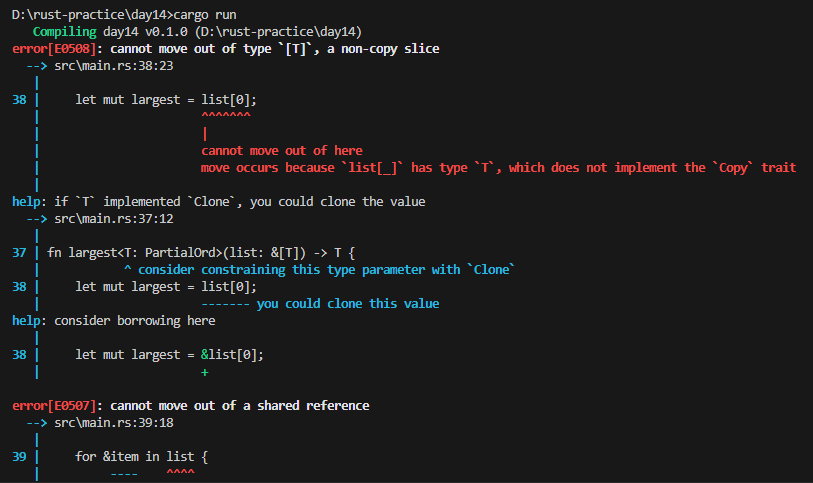
그래서 T 다음에 PartialOrd만 추가하고 Copy는 빼고 실행하면
let mut largest = list[0];의 list[0]에서 error[E0508]: cannot move out of type [T], a non-copy slice (복사할 수 없는 슬라이스인 `[T]` 유형에서 이동할 수 없습니다) 란 에러가 발생하고,
let mut largest = &list[0];에서는 type ‘T’가 Copy trait를 구현하지 않았기 때문에 move가 일어났는데, 여기서 data가 move될 수 없다고 합니다.
정수나 문자 타입에 공통적으로 적용하기 위해 제네릭 타입을 적용하는 것은 좋은데, 적용하기 위해 추가해야 할 요소들이 많습니다. 그리고, 두 개의 Trait을 연결하기 위해서는 +를 사용헸습니다.
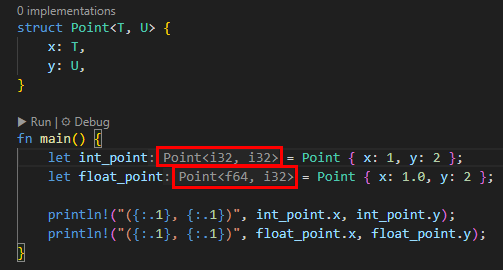
다. 구조체에 한 가지 제네릭 적용
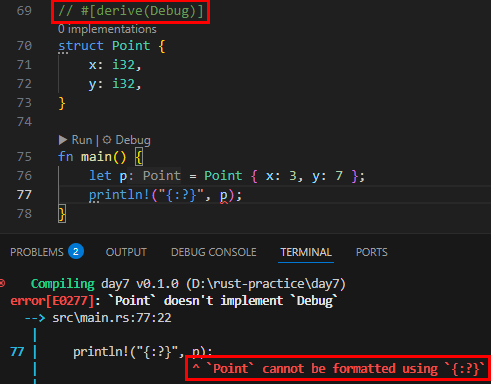
struct Point<T> {
x: T,
y: T,
}
fn main() {
let int_point = Point { x: 1, y: 2 };
let float_point = Point { x: 1.0, y: 2.0 };
println!("({:.1}, {:.1})", int_point.x, int_point.y);
println!("({:.1}, {:.1})", float_point.x, float_point.y);
}
위 코드의 경우 타입이 T 하나뿐이 없기 때문에, 타입이 한 가지인 경우만 적용가능합니다. 따라서 Point 구조체를 정의할 때 i32 또는 f64 타입 한 가지로만 지정했습니다.
그리고, {}라고 하면 실수인 경우에도 1로 출력이 돼서 {:.1}로 출력 형식을 변경했습니다.
라. 구조체에 두 가지 제네릭 적용
아래와 같이 하나의 구조체에 여러 타입, T와 U를 지정할 수 있습니다. 이 경우 T나 U는 특별한 의미가 있는 것이 아니고, 타입이 다르다는 것을 의미합니다.
struct Mixed<T, U> {
x: T,
y: U,
}
위에서 두 가지 타입을 지정했으므로 아래와 같이 i32와 f64를 같이하거나 달리해서 지정할 수 있습니다.
위 코드를 실행하면 (1, 2) (1.0, 2) 식으로 화면에 표시됩니다.
2. 트레잇(Trait)
트레잇은 공통된 동작을 정의하는 인터페이스입니다. 특정 타입이 트레잇을 구현하면, 해당 트레잇의 메서드를 사용할 수 있습니다.
Trait을 구현하는 방식은 impl Trait for Type으로서 impl Summary for Article이라고 적은 다음 중괄호 안에서 fn summarize로 메소드를 구현하는데, 인수는 &self로 자기 자신, 여기서는 Article을 받고, 반환 형식은 위에서 지정했듯이 String 타입이며, 구체적으로 실행하는 것은 format!(“{} by {}”, self.title, self.author)으로 self.title by self.author란 문자열을 생성합니다.
(4) main 함수에서 구조체 생성 및 트레잇 메소드 실행
main 함수에서는 구조체를 생성한 다음 aricle.summarize로 title과 author를 이용한 문자열을 만든(format) 후 println!로 화면에 출력합니다.
따라서, 위 코드를 실행하면 아래와 같이 “요약 : Rust 배우기 by 홍길동”이 출력됩니다.
나. 트레잇 바운드(Trait Bound)
함수 인자에서 트레잇을 사용하는 방법은 다음과 같이 세 가지가 있습니다.
(1) 케이스 1
item을 impl Summary로 지정하고, main 함수에서 notify 함수의 인수로 aritcle을 입력하는 것입니다.
Rust에서 복잡한 데이터를 다루기 위해 사용하는 기본 단위가 바로 구조체(struct)입니다. 구조체는 여러 개의 관련된 데이터를 하나의 타입으로 묶어 표현할 수 있도록 해줍니다. Rust는 구조체와 메서드(impl 블록)를 통해 모듈화, 캡슐화, 데이터 모델링이 가능합니다.
1. 기본 구조체 정의 및 사용
가장 기본적인 구조체는 struct 다음에 구조체 이름을 쓰고, 중괄호 안에 필드의 이름과 타입을 :으로 연결해 선언합니다.
Rust의 구조체 이름 규칙은 대문자 카멜 케이스(Camel case)입니다. 예를 들어 User, MySruct와 같이 단어 시작을 대문자로 하고, _를 사용할 수 있으며 숫자로 시작할 수 없고, 공백이 포함되면 안됩니다.
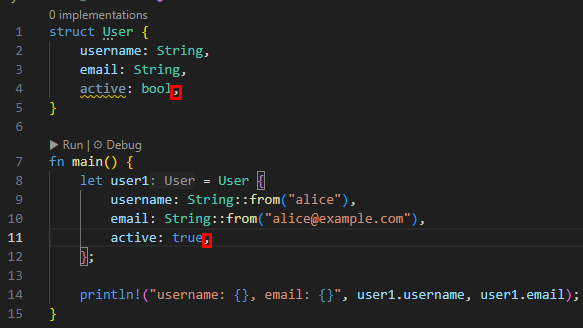
struct User {
username: String,
email: String,
active: bool,
}
사용할땐 struct의 인스턴스를 생성합니다.
일반 변수 선언할 때와 마찬가지로 let 키워드를 사용하고, 그 다음에 인스턴스 이름을 적고, = 구조체 이름을 적은 다음 중괄호안에 필드의 이름과 값을, key: value 쌍으로 아래와 같이 입력합니다. 구조체는 모든 필드의 타입이 명확해야 합니다.
fn main() {
let user1 = User {
username: String::from("alice"),
email: String::from("alice@example.com"),
active: true,
};
println!("username: {}", user1.username);
}
문자열(String)은 “alice”와 같이 큰따옴표 안에 입력한다고 되는 것이 아니며, String::from(“alice”)라고 하거나, “alice”.to_string()으로 입력해야 합니다.
bool(논리값)도 true, false와 같이 모두 소문자로 표기합니다.
필드 값을 끝까지 입력하고, 쉼표가 있어도 문제가 없습니다.
구조체 인스턴스는 tuple과 마찬가지로 . 연산자(notation)로 접근할 수 있습니다.
Rust는 사용하는 기호도 여러가지가 사용돼서 복잡합니다.
지금까지 나온 것이 변수의 형식은 : 다음에 표시하고, println다음에 !를 붙여야 하며, match 패턴의 경우 => 을 사용해서 실행 코드를 지정하고, else를 _로 표시하며, 숫자 입력시 천단위 구분 기호로 _를 사용하고, char를 입력할 때는 작은 따옴표, String을 입력할 때는 큰따옴표, 반환 값의 타입을 지정할 때는 ->, loop label은 ‘로 시작하며, 참조를 표시할 때는 &를 사용하고, 튜플과 구조체의 값을 지정할 때는 .을 사용합니다.
2. 구조체는 소유권을 가진다
Rust에서 구조체는 일반 변수처럼 소유권을 가집니다. 즉, 구조체를 다른 변수로 이동시키면 원래 변수는 더 이상 사용할 수 없습니다.
let user2 = user1; // user1의 소유권이 user2로 이동
// println!("{}", user1.email); // 오류!
필드 하나만 이동하는 경우도 마찬가지입니다.
let username = user1.username; // 소유권 이동 (user1.username에 대한 소유권은 종료됨)
// user1.username은 더 이상 유효하지 않음, username 변수가 소유권을 갖게 됨
println!("username: {}", username);
일부 필드를 참조로 처리하거나 클론(clone)을 사용해야 합니다.
let username = &user1.username;
또는
let username = user1.username.clone();
3. 기존 구조체 인스턴스로 새 구조체 인스턴스 생성하기
구조체 인스턴스를 만들 때 기존 구조체를 기반으로 일부 필드만 바꾸고 싶은 경우, 다음과 같이 .. 문법을 사용하여 나머지는 (user2와) 동일하다고 할 수 있습니다:
let user3 = User {
email: String::from("bob@example.com"),
..user2
};
단, user2는 이후 더 이상 사용할 수 없습니다. 그 이유는 username, email과 active 필드의 소유권이 user3에게로 넘어갔기 때문입니다.
또한 ..user2라고 나머지 필드는 똑같다고 할 때 맨 뒤에 ,를 붙이면 안됩니다. 구조체 정의할 때는 ,로 끝나도 되는 것과 구분됩니다.
4. 튜플 구조체 (Tuple Struct)
필드의 이름이 없고 형식만 있는 구조체도 정의할 수 있습니다. 이를 튜플 구조체라고 하며, 단순한 데이터 묶음에 유용합니다. 구조체 이름 다음이 중괄호가 아니라 소괄호인 것도 다릅니다.