nuitka가 python version 3.대와 맞지 않는다는 ChatGPT의 말에 따라 venv를 3.12.6으로 낮추고 nuitka –standalone –onefile df_base.py를 실행하니 python 3.13에서 nuitka 2.7.13이 실행된다는 메시지가 나옵니다. 그래서 python -m nuitka –standalone –onefile df_base.py를 하니 python 버전 3.12에서 실행됩니다.
1. python code
import pandas as pd
import numpy as np
import openpyxl # nuitka때문에 해야 하나?
index = pd.date_range('1/1/2000', periods=8)
print(index)
df = pd.DataFrame(np.random.rand(8,3),index = index, columns=list('ABC'))
df['D'] = df['A'] / df['B']
df['E'] = np.sum(df, axis=1)
df = df.sub(df['A'], axis=0)
df = df.div(df['C'], axis=0)
df.to_csv('test.csv')
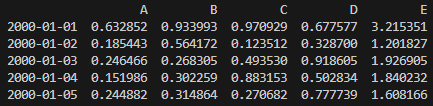
print(df.head())
# print(df)
df2 = df[df['B']>0.4].T
print(df2.head())
df.to_excel('날짜랜덤.xlsx', engine="openpyxl")import pandas as pd
import numpy as np
=> pandas와 numpy 라이브러리를 호출해서 각각 pd와 np라는 alias로 선언합니다.
index = pd.date_range(‘1/1/2000’, periods=8)
=> 2000/1/1부터 8개를 생성해서 index로 삼습니다.

dtype(데이터 형식)은 datetime64인데, ns는 nanosecond의 약자로 nanosecond까지 저장한다는 의미이고,
freq는 frequency의 약자로 D(날짜), 다시 말해 1일 단위라는 것입니다.
print(index)
=> index를 화면에 출력합니다.
df = pd.DataFrame(np.random.rand(8,3),index = index, columns=list(‘ABC’))
=> random 함수로 0과 1사이의 숫자를 8행 3열로 생성하고, index는 위에서 생성한 index 변수로 지정하고, column은 A,B,C로 함.
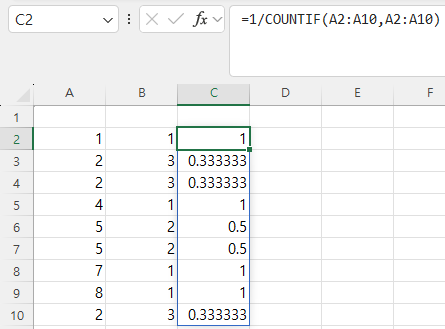
df[‘D’] = df[‘A’] / df[‘B’]
=> A열을 B열로 나눠 D열을 생성해서 값을 넣고
df[‘E’] = np.sum(df, axis=1)
=> df에 E열을 생성해서 행별 합계를 넣습니다.
| 구분 | 장점 | 주의점 |
|---|---|---|
| np.sum(df, axis=1) | 빠름, NumPy 배열과 함께 사용 시 효율적 | DataFrame에 숫자가 아닌 값이 있으면 오류 |
| df.sum(axis=1) | pandas 데이터에 최적화, numeric_only 옵션으로 안전 | 속도는 NumPy보다 조금 느림 |
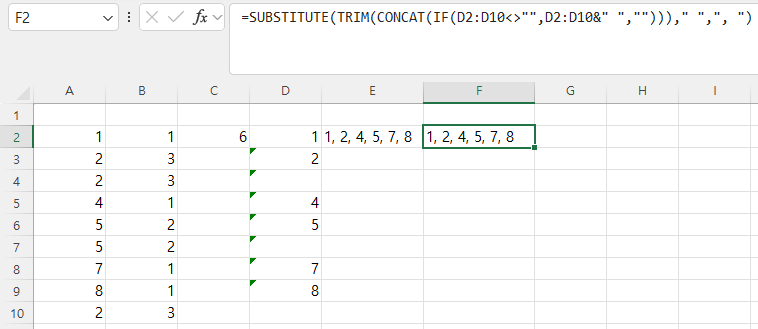
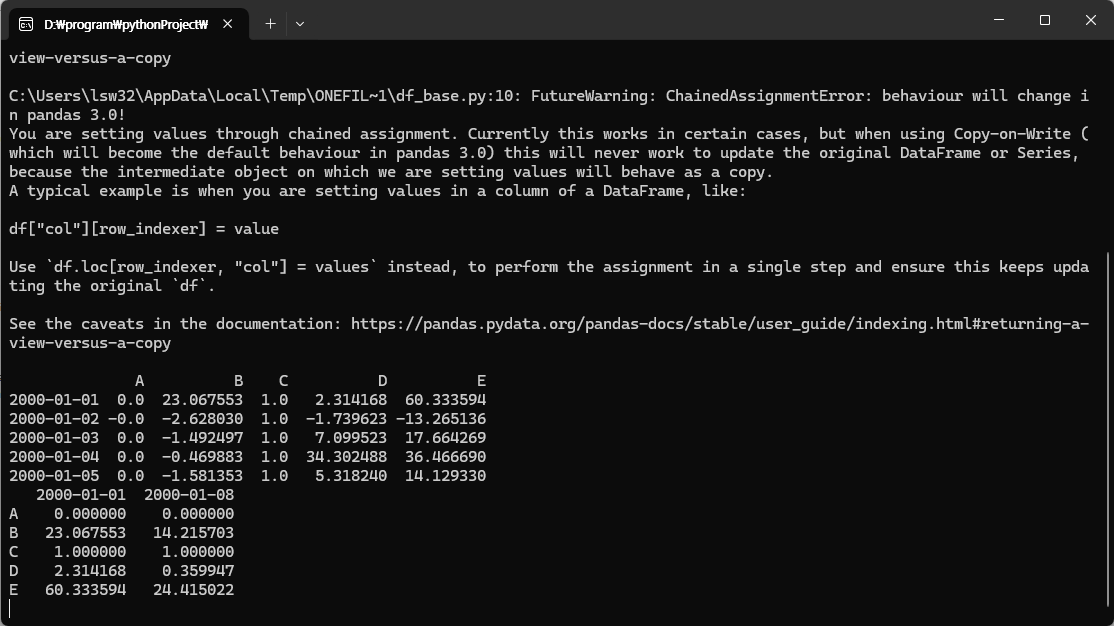
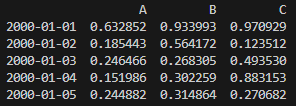
df = df.sub(df[‘A’], axis=0)
=> 모든 열에서 A열의 값을 빼서 새로운 df를 생성합니다.
아래는 5개만 출력해서 5일까지만 보이는 것입니다.
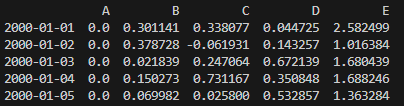
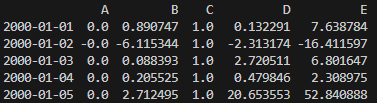
위 표에서 2000-01-01의 B값은 당초 0.933993에서 A값인 0.632852을 빼서 0.301141이 된 것입니다. 이런 식으로 모든 열에서 A열의 값을 빼서 기록한 것입니다.
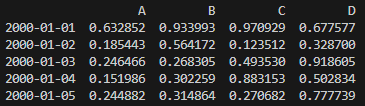
df = df.div(df[‘C’], axis=0)
=> 모든 열의 값을 C열 값으로 나눠서 새로운 df를 생성합니다.
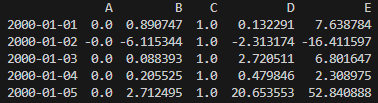
위 표에서 2000-01-01의 B값은 당초 0.301141을 C값인 0.338077으로 나눠서 0.890747이 된 것입니다. 이런 식으로 모든 열을 C열의 값으로 나눠서 기록한 것입니다.
df.to_csv(‘test.csv’)
=> df를 test.csv 파일로 저장합니다.
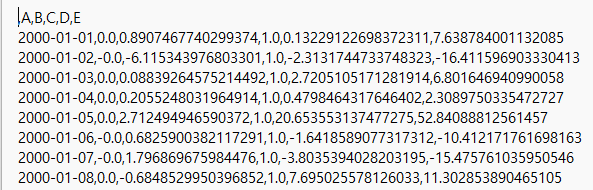
csv 파일을 열어보면 아래와 같이 ,(쉼표)로 열이 구분되어 있고, 소숫점이하 자릿수가 화면에 표시되는 것보다 훨씬 많아 15~17자리로 표시됩니다.
print(df.head())
=> df의 값을 처음부터 5개 화면에 출력합니다.
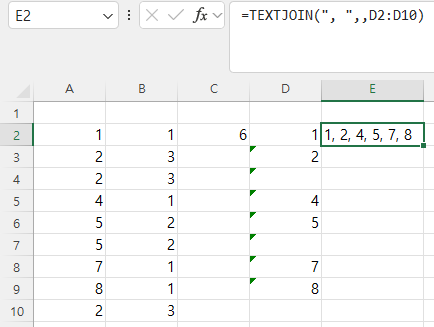
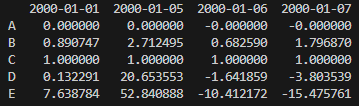
df2 = df[df[‘B’]>0.4].T
=> B열이 0.4보다 큰 것만을 구해서 df에 넣고,
Transpose, 다시 말해 행과 열을 바꾼 후 df2라는 새로운 데이터프레임에 넣습니다.
print(df2.head())
=> df2 데이터프레임 중 첫 5개를 화면에 출력합니다.
B열을 기준으로 0.4보다 큰 행만 고르기때문에 1/1, 1/5, 1/6, 1/7만 추출됐고, 행/열 전환이 되다보니 아래와 같이 표시됩니다.
df.to_excel(‘날짜랜덤.xlsx’, engine=”openpyxl”)
=> df를 날짜랜덤.xlsx라는 엑셀 파일로 저장하는데, openpyxl을 사용합니다.
날짜가 시,분,초까지 표시되고, 숫자는 저장하지를 않아서 다르지만, 참고로 보기 바랍니다.

2. 실행 파일 만들기
그동안 pyinstaller를 사용했는데, nuitka(뉴트카)가 실행속도가 빠르다고 해서 해보는데, 다른 실행파일 생성 도구와 비교할 때 장,단점은 아래와 같습니다.
가. Python 실행파일 생성 도구 정리
| 도구 | 특징 | 장점 | 단점 |
|---|---|---|---|
| PyInstaller | 스크립트를.exe로 묶음 | 사용 쉽고 자료 많음, GUI/CLI 모두 지원 | 일부 대형 라이브러리(TensorFlow 등) 복잡, 초기 실행 느림 |
| cx_Freeze | 비슷하게 스크립트 묶음 | 안정적, 초기 실행 빠름 | 설정 조금 까다로움 |
| Nuitka | 파이썬을 C로 변환 후 컴파일 | 실행 속도 빠르고 네이티브, 소스 보호 | 빌드 느림, 대형 프로젝트는 빌드 복잡 |
| py2exe | 윈도우 전용 | 단순 CLI/GUI에 가벼움 | 윈도우 전용, 유지보수 제한적 |
| UV (UltraViolet / uv-py?) | 최근 언급되는 Python 컴파일러 | 비교적 빠름, 단일 실행파일 생성 가능 | 자료가 적고 안정성 검증 필요 |
PC에 파이썬 버전이 여러 개 있을 경우 실행 방법이 다르다는 것을 이제야 알았습니다.
나. nuitka로 바로 실행하기
nuitka –standalone –onefile df_base.py
로 바로 실행하니 venv는 3.12.6인데

Nuitka: Version ‘2.7.13’ on Python 3.13 … 이라고 파이썬 버전 3.13에서 실행됩니다.

그래서 계속 3.13에서 실행 파일 만드면 openpyxl 모듈이 없다는 에러 메시지가 떠서
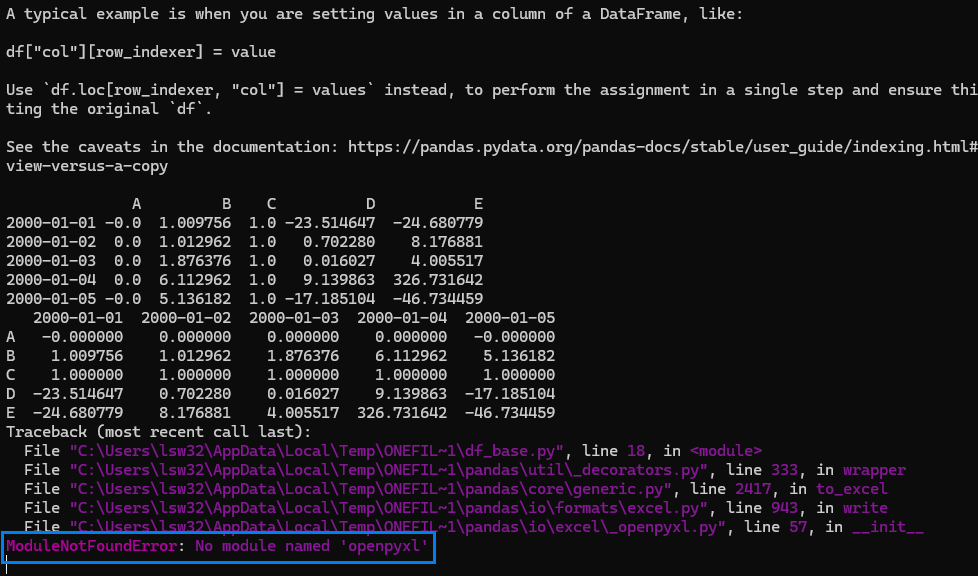
Ctrl + C키를 눌러 실행을 중단시켰습니다.
다. python -m nuitka로 실행하기
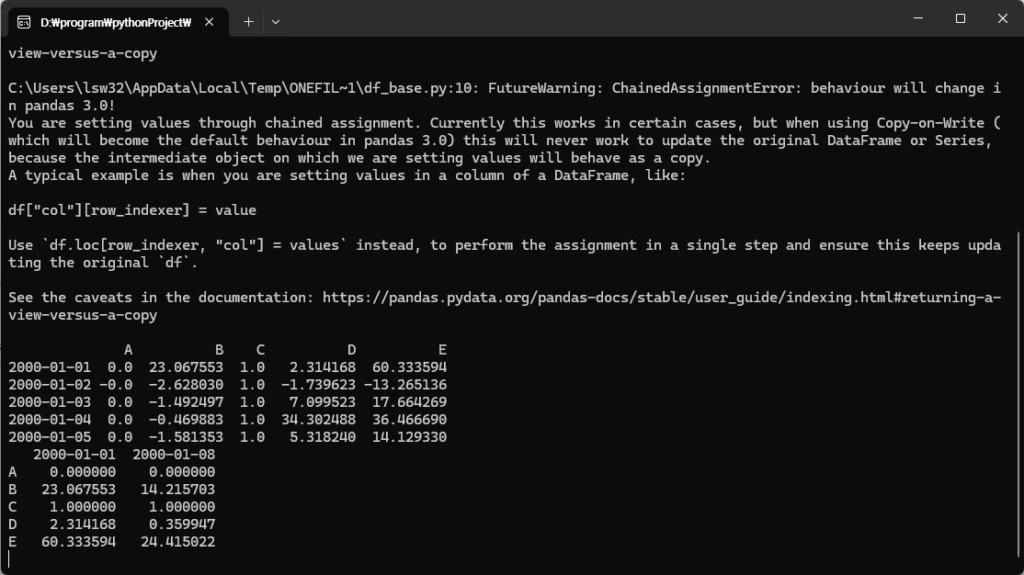
그런데 python -m 다음 nuitka 명령을 넣어 실행하니

python 버전이 3.13이 아니라 3.12로 바뀝니다.
라. 실행 파일 실행
그리고, 실행하니 아무런 에러 메시지 없이 잘 됩니다.
마. 코드 수정
python 3.13 버전에서 컴파일시 openpyxl 라이브러리를 import하려면 import openpyxl이 있어서 한다고 해서 넣었었는데, python 3.12에서는 필요 없어서 뺐고,
df.to_excel(‘날짜랜덤.xlsx’, engine=”openpyxl”)에서도
openpyxl을 강제로 import하도록 넣어야 한다고 해서 넣고 컴파일 했었는데, 3.13에서는 결국은 안되고, 3.12에서는 필요가 없어서 뺐습니다.
바. pyinstaller는 .\.venv\pyinstaller로 실행
아무 생각없이 pyinstaller를 pyinstaller -F -w df_base.py로 실행하니 아래와 같은 에러가 발생해서
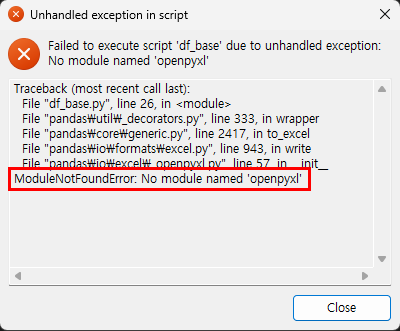
컴파일 과정을 살펴보니 마찬가지로 python 버전이 3.13으로 실행됐네요.
그런데 nuitka와 마찬가지로 python -m pyinstaller -F -w df_base.py라고 하니
pyinstaler가 있는데, pyinstaller 모듈이 없다고 나옵니다.

그래서 .venv\Scripts\pyinstaller.exe -F -w df_base.py
로 해야 합니다.

경우에 따라 많이 다르네요.
그리고, 또 하나의 차이점은 pyinstaller의 경우는 .\dist 폴더에 실행파일이 생기는데,
nuitka의 경우는 .py 폴더에 생깁니다.