::은 “어디에 속한 항목인지” 또는 “어떤 타입인지”를 명시할 때 쓰이며, enum일 수도, 모듈일 수도, 제네릭 타입 지정(Turbofish)일 수도 있으며, 연관 함수, 상수 또는 연관 상수에 접근할 때도 사용되고, 트레이트 경로를 통한 메소드 호출 시에도 사용됩니다.
1. Rust에서 ::의 용도 정리표
구분
예시
설명
관련 키워드
모듈/경로 구분자
std::fs::File
모듈(std) → 하위 모듈(fs) → 항목(File)로 내려가는 경로 지정
모듈(module), 네임스페이스(namespace)
enum variant 접근
Option::Some(5)
Optionenum 안의 Somevariant에 접근
enum
연관 함수(associated function) 접근
String::from(“hi”)
타입(String)의 연관 함수(from) 호출
struct, enum, trait
상수 또는 연관 상수 접근
std::f64::consts::PI
f64타입의 연관 상수 PI에 접근
상수(const)
Turbofish (제네릭 타입 명시)
“42”.parse::<i32>()
제네릭 함수의 타입 매개변수를 명시적으로 지정
제네릭(Generic)
제네릭 타입 생성 시 타입 지정
Vec::<i32>::new()
제네릭 타입(Vec<T>)의 매개변수를 명시적으로 지정
제네릭 타입
트레이트 경로를 통한 메서드 호출
<T as SomeTrait>::method()
특정 트레이트에 정의된 메서드를 명시적으로 호출
트레이트(impl 충돌 해결용)
2. 예시 모음
mod math {
pub const PI: f64 = 3.14;
}
#[derive(Debug)]
#[allow(dead_code)]
enum Color {
Red,
Blue,
}
fn main() {
// 1️⃣ 모듈 경로
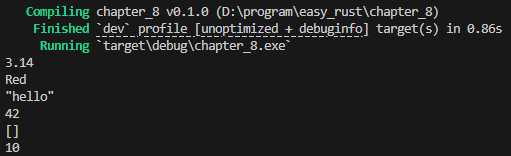
println!("{}", math::PI); // -> 3.14
// 2️⃣ enum variant 접근
let c = Color::Red;
println!("{c:?}");
// 3️⃣ 연관 함수
let s = String::from("hello");
println!("{s:?}");
// 4️⃣ Turbofish
let n = "42".parse::<i32>().unwrap();
println!("{n:?}");
// 5️⃣ 제네릭 타입 지정
let v = Vec::<i32>::new();
println!("{v:?}");
// 6️⃣ 트레이트 메서드 명시 호출
use std::string::ToString;
let x = 10;
let s = <i32 as ToString>::to_string(&x);
println!("{}", s); // "10"
}
use aggregator::summarize;
fn main() {
let text = "Rust makes systems programming fun and safe!";
let summary = summarize(text);
println!("{}", summary);
}
7. Build and run
From the workspace root:
cargo run -p aggregator_app
Output:
Summary: Rust makes systems programming fun and safe!
✅ Now you have:
aggregator → library crate
aggregator_app → binary crate
managed together in one workspace.
Ⅱ. How to Test the Library
Let’s extend the workspace so you can test your aggregator library while also running the app. There are two ways to test library, one is adding tests inside the library and the other is adding separate integration tests in a tests/ directory
1. Add tests inside the library
Edit aggregator/src/lib.rs:
/// Summarize a given text by prefixing it.
pub fn summarize(text: &str) -> String {
format!("Summary: {}", text)
}
// Unit tests go in a special `tests` module.
#[cfg(test)]
mod tests {
// Bring outer functions into scope
use super::*;
#[test]
fn test_summarize_simple() {
let text = "Hello Rust";
let result = summarize(text);
assert_eq!(result, "Summary: Hello Rust");
}
#[test]
fn test_summarize_empty() {
let text = "";
let result = summarize(text);
assert_eq!(result, "Summary: ");
}
}
2. Run the tests
From the workspace root:
cargo test -p aggregator
Output (example):
running 2 tests
test tests::test_summarize_simple ... ok
test tests::test_summarize_empty ... ok
test result: ok. 2 passed; 0 failed
3. Run the app
From the same root:
cargo run -p aggregator_app
Output:
Summary: Rust makes systems programming fun and safe!
4. (Optional) Integration tests
You can also add separate integration tests in a tests/ directory inside the aggregator crate:
use aggregator::summarize;
#[test]
fn integration_summary() {
let text = "Integration testing is easy!";
let result = summarize(text);
assert_eq!(result, "Summary: Integration testing is easy!");
}
Run all tests in the workspace:
cargo test
✅ Now you have:
Unit tests inside src/lib.rs
Integration tests in tests/
Ability to run tests and app from the same workspace.
Mut는 “변수의 값을 바꿀 수 있다(mutable)”는 의미이고, Shadowing은 “같은 변수명을 사용해서 이전의 변수를 가리는” 기능입니다. Shadowing을 통해 Mut의 기능을 대체할 수도 있고, 둘 다 사용하지 않는다면 변수명을 여러 개 사용해야 하는 번거로움이 있습니다.
1. Mut를 사용한 경우
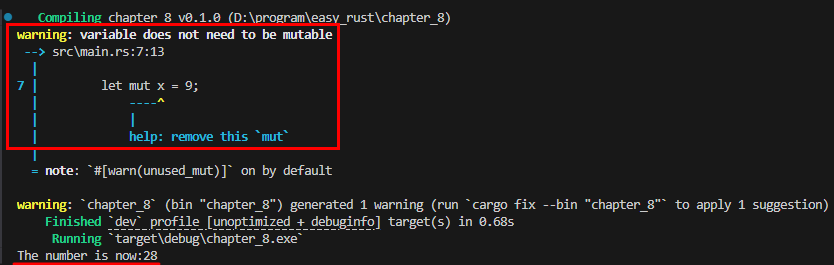
아래 예시는 x를 mutable(가변) 변수로 선언한 다음 => let mut x = 9;
x의 값을 바꿔가면서 원하는 값인 final_number를 출력하는 코드입니다. => x = times_two(x); => x = x + y; 이 때 반환값은 x라고 ;없이 씁니다.
fn times_two(number: i32) -> i32 {
number * 2
}
fn main() {
let final_number = {
let y = 10;
let mut x = 9;
x = times_two(x);
x = x + y;
x
};
println!("The number is now:{}", final_number);
}
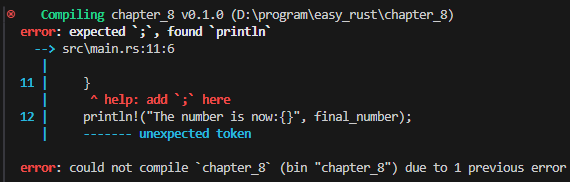
그러나, let final_number가 끝나는 지점에는 let 문이므로 ;을 반드시 붙여야 합니다. 안 붙이면 아래와 같이 ;을 기대했는데, println이 발견됐다는 에러가 표시됩니다.
Rust의 특이한 점이 불변(immutable)이 변수의 기본 상태이고, 변수의 값을 바꿀 수 있게 하려면 mut를 붙여야 한다는 점입니다.
※ 함수 구문
fn times_two(number: i32) -> i32 {
number * 2
}
Rust에서 함수를 선언할 때는 fn을 사용하고 그 다음에 함수명을 붙이는 것은 다른 언어와 같습니다.
그 다음 괄호 안에 인수명을 입력하는데, 여기서는 number이고,
반드시 인수의 타입을 입력해야 하는데, : 다음에 i32 식으로 “32비트 부호 있는 정수” 타입이라고 명시합니다.
이것이 변수의 경우 추론(inference)이 돼서 타입을 반드시 기재해야 할 필요가 없는 것과 다른 점입니다. 변수의 경우 정수는 i32, 실수는 f64가 기본형입니다.
그리고, 반환 값이 있으면 반환 값의 형식도 입력해야 하는데, -> 다음에 i32식으로 입력합니다.
따라서, 반환값이 없으면 ‘-> 반환 값 형식’을 입력하지 않습니다.
그리고, 중괄호 안에 함수의 내용을 기록하고, 반환값을 마지막에 입력하는데, 여기서는 반환값이 number * 2로 인수에 2를 곱한 값을 반환하는 것인데, 마지막에 ;을 붙이지 않는 것도 중요한 점의 하나입니다.
2. Shadowing을 사용한 경우
Shadowing은 “그림자처럼 따라 다님”이란 의미이므로, 여기서는 원래 있던 x 변수를 가리는 역할을 합니다.
Shadowing을 이용하게 되면 x = 을 let x =이라고 쓰고, 처음 변수 선언할 때 mut 없이 let x = 9;이라고 씁니다.
fn times_two(number: i32) -> i32 {
number * 2
}
fn main() {
let final_number = {
let y = 10;
let x = 9;
let x = times_two(x);
let x = x + y;
x
};
println!("The number is now:{}", final_number);
}
만약 let mut x = 9;라고 mut를 붙여도 결과는 같지만, ‘변수가 mutable일 필요가 없다”는 경고와 mut를 제거하라는 도움말이 표시됩니다.
3. shadowing과 mut를 사용하지 않은 경우
fn times_two(number: i32) -> i32 {
number * 2
}
fn main() {
let final_number = {
let y = 10;
let x = 9;
let twice_x = times_two(x);
let twice_x_and_y = twice_x + y;
twice_x_and_y
};
println!("The number is now:{}", final_number);
}
1과 2 예제에서는 변수명으로 x 하나만을 사용했는데,
이번 예제 3에서는 x, twice_x, twice_x_and_y라는 변수 3개를 사용해야 해서 매우 번거롭습니다.
러스트의 경우 처음에 명령 프롬프트 창에서 포트를 열어놓고 Cargo run을 하라고 하여 Python은 포트를 열 필요없이 잘 접속되는데 해서 비교하게 되었습니다. 그리고, 보면 파이썬은 편리한 상태를 만들어 놓았는데, Rust는 처음부터 내가 만들어가야 하는 상황입니다.
Chromedriver가 Path에 있다면 그냥 실행하면 되는데, path가 설정되어 있지 않아, chromedriver.exe가 있는 폴더로 이동해서 실행했습니다.
(2) 브라우저 열기 Rust 코드
(가) Cargo.toml
[dependencies]
thirtyfour = "0.36.1"
tokio = { version = "1", features = ["full"] }
thirtyfour와 tokio 라이브러리를 가져와야 합니다.
(나) main.rs
use thirtyfour::prelude::*;
use tokio;
#[tokio::main]
async fn main() -> WebDriverResult<()> {
// 이미 chromedriver가 9515 포트에서 실행 중이라고 가정
let driver = WebDriver::new("http://localhost:9515", DesiredCapabilities::chrome()).await?;
// 페이지 접속
driver.get("https://www.rust-lang.org").await?;
// 타이틀 가져오기
let title = driver.title().await?;
println!("Page title: {}", title);
// 종료
driver.quit().await?;
Ok(())
}
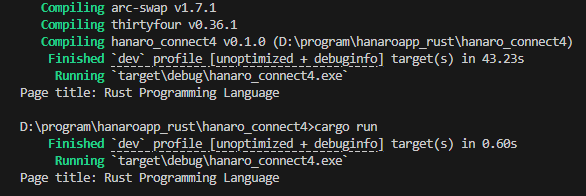
코드이 내용은 port가 열려 있기 때문에 다시 열 필요는 없고, 9515 포트로 driver를 설정한 다음, rust-lang.org에 접속한 후 title을 가져와서 화면에 출력하는 것입니다.
문제 없이 코드가 실행되고, title이 표시됩니다.
나. 코드로 포트 열기 방식
명령 프롬프트에서 포트를 연 다음 Cargo run을 한다는 것이 이상하므로 Rust에서 포트를 열고, 실행하려면 아래와 같이 코드를 작성하면 됩니다.
Cargo.toml은 동일하고,
main.rs만 아래와 같이 수정하면 됩니다.
use std::process::Command;
use thirtyfour::prelude::*;
use tokio;
#[tokio::main]
async fn main() -> WebDriverResult<()> {
// 실행파일이 있는 디렉토리 경로
let exe_dir = std::env::current_exe()
.unwrap()
.parent()
.unwrap()
.to_path_buf();
let chromedriver_path = exe_dir.join("chromedriver.exe");
println!("chromedriver 경로: {}", chromedriver_path.display());
// chromedriver 실행
let mut child = Command::new(&chromedriver_path)
.arg("--port=9515")
.spawn()
.expect("chromedriver 실행 실패");
// WebDriver 클라이언트 연결
let caps = DesiredCapabilities::chrome();
let driver = WebDriver::new("http://localhost:9515", caps).await?;
driver.get("https://www.rust-lang.org").await?;
println!("현재 페이지 타이틀: {}", driver.title().await?);
// 브라우저 닫기
driver.quit().await?;
// chromedriver 프로세스 종료
child.kill().ok();
Ok(())
}
use std::process::Command;가 추가되었습니다.
main에서 먼저 chromedriver_path를 설정하고,
Command::new를 이용해 포트를 연 다음 child에 저장하고,
caps는 python Selenium에서 사용하는 ChromeOptions 역할입니다. 기본적인 옵션만 설정하는 것입니다. caps.add_arg(“–headless”)?; 등을 추가해서 옵션을 추가할 수 있습니다.
그리고, WebDriver::new로 http://localhost:9515라고 9515포트를 이용해 localhost를 연 다음
driver.get로 https://www.rust-lang.org를 연 다음
driver.title().await?로 title을 가져와서 화면에 출력합니다.
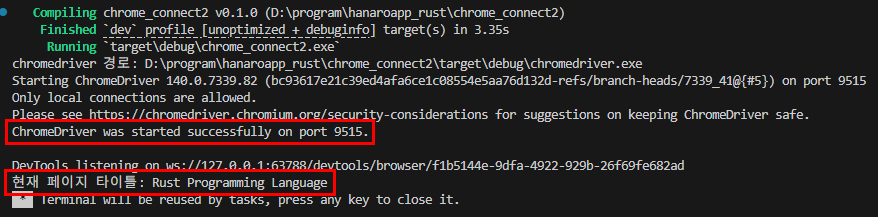
아래는 Visual Studio Code에서 Run한 장면입니다.
Compile과 실행 잘 되고, ChromeDriver was started successfully on port 9515.와
현재 페이지 타이틀 : Rust Programming Language라고 잘 나옵니다.
2. Python을 이용한 웹 접속
가. chrome_connect.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import os
def main():
# 실행 파일이 있는 디렉토리 기준으로 chromedriver.exe 찾기
exe_dir = os.path.dirname(os.path.abspath(__file__))
chromedriver_path = os.path.join(exe_dir, "chromedriver.exe")
# chromedriver.exe 고정 경로
# chromedriver_path = r"C:\android\chromedriver.exe"
# print(f"chromedriver 경로: {chromedriver_path}")
# chromedriver 실행 (포트 지정 없이 내부적으로 관리)
service = Service(chromedriver_path)
options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=service, options=options)
try:
driver.get("https://www.rust-lang.org")
print(f"현재 페이지 타이틀: {driver.title}")
finally:
driver.quit()
if __name__ == "__main__":
main()
Python은 Cargo.toml과 같은 설정이 필수가 아니고,
바로 python code를 위와 같이 작성하면 됩니다.
실행 결과는 아래와 같습니다.
나. 코드 내용
from selenium import webdriver from selenium.webdriver.chrome.service import Service import os
필요한 selenium과 os 라이브러리를 불러옵니다.
# 실행 파일이 있는 디렉토리 기준으로 chromedriver.exe 찾기
exe_dir = os.path.dirname(os.path.abspath(__file__))
chromedriver_path = os.path.join(exe_dir, "chromedriver.exe")
# chromedriver.exe 고정 경로
# chromedriver_path = r"C:\android\chromedriver.exe"
실행 파일이 있는 폴더의 chromedriver.exe를 chromedriver_path로 설정합니다.
주석 처리한 것처럼 고정 경로로 지정할 수도 있습니다. 여러 프로그램에서 공통적으로 사용할 수 있으므로 PC에서만 작업한다면 이것이 편할 수 있습니다.
print(f"chromedriver 경로: {chromedriver_path}")
chromedriver_path를 화면에 출력합니다.
# chromedriver 실행 (포트 지정 없이 내부적으로 관리) service = Service(chromedriver_path) options = webdriver.ChromeOptions()
Service 메소드를 이용해 service를 생성하고, webdriver.ChromeOptions()로 크롬 설정을 기본으로 합니다.
자바(Java)는 모든 메소드를 클래스 내부에 정의합니다. 그러나, 러스트(Rust)는 데이터 구조(Struct)와 메소드(Impl block)가 물리적으로 분리되어 있습니다. 구조체 안에는 데이터만 정의하고, 별도의 impl 블록에서 그 구조체에 대한 메소드를 구현합니다.
Ⅰ. 데이터 구조, 메소드 구현 방식 비교
1. 자바: 클래스 내부에 메소드
자바(Java)는 모든 메소드를 클래스 내부에 정의합니다. 이는 객체 지향 프로그래밍(OOP)의 특징으로, 데이터(필드)와 행동(메소드)이 하나의 단위(클래스)에 밀접하게 결합(cohesion)되어 있습니다.
2. 러스트: 구조체와 메소드의 분리
러스트(Rust)에서는 데이터 구조(Struct)와 메소드(Impl block)가 물리적으로 분리되어 있습니다. 구조체 안에는 데이터만 정의하고, 별도의 impl 블록에서 그 구조체에 대한 메소드를 구현합니다.
3. 장단점
구분
자바(메소드=클래스 내부)
러스트(메소드=구조체 외부)
응집성
데이터와 행동이 하나에 묶임
데이터와 행동이 분리되어 명확
확장성
상속 등 OOP 구조 확장 용이
Trait, 여러 impl로 유연하게 확장
가독성
클래스 안에서 한 번에 파악 가능
데이터 정의와 메소드 구현 분리
유연성
하나의 클래스가 하나의 메소드 집합
같은 구조체에 여러 impl, trait 구현 가능
재사용성
상속, 인터페이스로 구현
Trait 등으로 다양한 방식의 재사용
관리의 용이성
대형 클래스에서 복잡해질 수 있음
관련 없는 메소드를 구조체와 별도 구현 가능
코드 조직화
OOP 방식(클래스-중심)
데이터 중심(struct), 행동 분리(impl, trait)
자바는 객체 중심의 응집력, 개발 및 이해 용이성이 강점이나, 큰 클래스가 복잡해지거나 상속 구조의 한계 등이 있습니다.
러스트는 데이터와 행동의 분리로 역할이 명확하며, trait 기반의 확장성과 안전성이 강점이지만, 초보자에겐 코드 연관성 파악이 다소 불편할 수 있습니다.
Ⅱ. 예제를 통한 비교
1. 자바(Java)
자바에서는 데이터(필드)와 메소드가 한 클래스 내부에 정의되어 객체 지향 프로그래밍 패러다임에 맞춰 응집되어 있습니다.
public class Point { private int x; private int y;
// 생성자 public Point(int x, int y) { this.x = x; this.y = y; }
// 메소드: 두 점 사이 거리 계산 public double distance(Point other) { int dx = this.x - other.x; int dy = this.y - other.y; return Math.sqrt(dx * dx + dy * dy); }
// getter 메소드 public int getX() { return x; } public int getY() { return y; } }
// 사용 public class Main { public static void main(String[] args) { Point p1 = new Point(0, 0); Point p2 = new Point(3, 4); System.out.println(p1.distance(p2)); // 출력: 5.0 } }
특징: Point 클래스 내부에 데이터(x, y)와 동작(거리 계산 메소드)을 모두 포함.
장점: 객체 지향적 응집성(cohesion) 강화, 한 곳에서 모든 관련 기능 파악 가능.
단점: 클래스가 커질수록 복잡성 증가, 상속 구조 제한 등.
2. 러스트(Rust)
러스트는 데이터 구조체(struct)와 메소드 구현부(impl 블록)를 분리해서 작성합니다. 이로써 역할 분리가 명확해지고, 여러 impl 블록과 trait을 통해 유연하게 확장할 수 있습니다.
// 데이터 정의: 구조체는 필드만 가짐 struct Point { x: i32, y: i32, }
// 메소드 구현: impl 블록에서 정의 impl Point { // 연관 함수(정적 메서드와 유사) fn new(x: i32, y: i32) -> Point { Point { x, y } }
// 메소드: 두 점 사이 거리 계산 fn distance(&self, other: &Point) -> f64 { let dx = (self.x - other.x) as f64; let dy = (self.y - other.y) as f64; (dx.powi(2) + dy.powi(2)).sqrt() } }
fn main() { let p1 = Point::new(0, 0); let p2 = Point::new(3, 4); println!("{}", p1.distance(&p2)); // 출력: 5.0 }
특징: struct는 데이터만 선언, 메소드는 별도의 impl 블록에서 구현.
장점: 데이터와 행동이 분리되어 역할 명확, 여러 impl이나 trait로 기능 확장 유리, 컴파일타임 안전성 증대.
단점: 관련 데이터와 메소드가 코드상 분리되어 있어 한눈에 파악하기 어려울 수 있음, 전통적인 OOP 방식과 차이 있음.
3. 비교 표
항목
자바(Java)
러스트(Rust)
구조
클래스 내부에 데이터와 메소드가 함께 있음
구조체(데이터)와 impl 블록(메소드)로 분리
작성 방식
한 클래스 파일 내에서 모든 정의
struct로 데이터 정의, 별도 impl로 메소드 구현
확장성
상속과 인터페이스 기반 확장 (단일 상속)
여러 impl 블록과 trait 조합으로 유연하고 다중 확장 가능
가독성
관련 데이터와 메소드가 한 곳에 있어 파악 용이
데이터와 메소드가 분리되어 코드가 흩어질 수 있음
안전성
런타임 검사 및 가비지 컬렉션
컴파일 타임 소유권 및 빌림 검사로 메모리 안전성 강화
메모리
참조 타입 중심, 힙 할당 및 가비지 컬렉션 필요
값 타입 중심, 명확한 메모리 제어 및 성능 최적화 가능
객체 지향
전통적인 OOP 완전 지원
클래스는 없으나 trait로 인터페이스 역할 및 객체지향 유사 기능 제공
러스트의 구조체+impl 방식은 자바와는 다르게 데이터와 메소드가 분리되어 있지만, impl 블록 내에서 메소드를 묶어 객체 지향적 프로그래밍의 많은 특징을 흉내 낼 수 있습니다. trait를 활용하면 인터페이스 역할도 하며, 상속 대신 다중 trait 구현으로 유연하게 기능을 확장할 수 있습니다.
Ⅲ . 자바의 상속과 인터페이스 구조와 러스트의 고급 Trait(트레이트) 및 패턴 비교
자바의 상속과 인터페이스 구조와 러스트의 고급 Trait(트레이트) 및 패턴을 심도 있게 비교 설명하면 다음과 같습니다.
1. 자바의 상속과 인터페이스 구조
가. 상속 (Inheritance)
클래스 간에 “is-a” 관계를 표현하는 가장 기본적인 메커니즘입니다.
한 클래스가 다른 클래스(부모 클래스)를 상속받아 멤버 변수와 메소드를 재사용하거나 오버라이드할 수 있습니다.
단일 상속만 지원하여 다중 상속의 복잡성을 회피합니다.
상속 구조가 깊어지면 유지보수가 어려워지고, 부모 클래스 변경 시 자식 클래스에 의도치 않은 영향이 발생할 수 있음.
나. 인터페이스 (Interface)
여러 클래스가 구현해야 하는 메소드의 명세(계약)를 정의합니다.
자바 8부터는 디폴트 메소드 구현도 지원하여 일부 기능적 확장 가능.
인터페이스의 다중 구현이 가능해 상속 단점을 보완하고 다형성 제공.
인터페이스는 구현 메소드가 없거나 기본 구현만 제공하므로, 설계 시 유연성을 줌.
interface Flyer { void fly(); } class Bird implements Flyer { public void fly() { System.out.println("Bird is flying"); } } class Airplane implements Flyer { public void fly() { System.out.println("Airplane is flying"); } }
2. 러스트의 고급 Trait 및 패턴
가. Trait(트레이트) 개념
러스트의 트레이트는 특정 기능을 구현하도록 강제하는 인터페이스 역할을 합니다.
타입에 따라 여러 트레이트를 다중으로 구현할 수 있어 매우 유연합니다.
트레이트 내에 메소드 기본 구현(default method)을 제공해 부분 구현도 가능.
Trait는 다중 상속을 대체하며, 조합(composition) 및 다형성을 지원합니다.
나. 고급 트레이트 특징
(1) 동일 메소드명을 가진 다중 트레이트 구현 (충돌 해결)
예를 들어, 같은 이름 fly() 메소드를 가진 서로 다른 트레이트 Pilot, Wizard를 Human 타입에 모두 구현 가능.
호출 시 Pilot::fly(&human), Wizard::fly(&human)처럼 트레이트 이름을 명시해 충돌 해결.
fn main() { let person = Human; Pilot::fly(&person); // This is your captain speaking. Wizard::fly(&person); // Up! person.fly(); // *waving arms furiously* }
(2) 슈퍼 트레이트 (Super-traits)
한 트레이트가 다른 트레이트의 구현을 전제로 하는 경우 사용.
예: OutlinePrint 트레이트가 Display 트레이트를 반드시 구현한 경우에만 구현 가능하도록 제한.
use std::fmt::Display;
trait OutlinePrint: Display { fn outline_print(&self) { // Display 기능 이용해 출력하는 구현 println!("*{}*", self); } }
(3) 제네릭과 트레이트 바운드 (Trait Bounds)
함수, 구조체, 열거형 등에서 트레이트를 타입 매개변수 조건으로 지정하여 유연한 재사용성 제공.
Rust에서의 attribute(속성)는 컴파일러에게 특정 코드에 대한 추가적인 정보를 제공하여, 코드의 컴파일 방식 또는 동작 방식을 제어하거나, 경고/에러 메시지를 제어하는 데 사용됩니다. derive, allow, warn, cfg, test 등 다양한 종류가 있습니다.
1. attribute의 적용 범위별 종류
Rust의 attribute는 크게 다음과 같은 종류로 나눌 수 있습니다:
종류
형태 예시
설명
Item attribute
#[derive(Debug)]
함수, 구조체 등 개별 항목에 적용
Crate attribute
#![allow(dead_code)]
크레이트 전체에 적용, 보통 파일 상단에 위치
Inner attribute
#![cfg(test)]
모듈 또는 크레이트 내부에 선언, 내부 항목에 영향을 줌
Outer attribute
#[test]
특정 항목(함수 등)에만 적용
2. 주요 attribute
가. 컴파일러 관련 attribute
Attribute
설명
예시
#[allow(…)]
특정 경고를 무시
#[allow(dead_code)]
#[warn(…)]
경고를 표시 (기본값)
#[warn(unused_variables)]
#[deny(…)]
해당 사항이 있으면 컴파일 에러
#[deny(missing_docs)]
#[forbid(…)]
deny보다 강하게 재정의 불가
#[forbid(unsafe_code)]
나. 파생(derive) 관련 attribute
Rust의 많은 기능은 trait을 자동으로 구현해주는 #[derive(…)]를 통해 사용합니다.
“my_feature”라는 기능(feature)이 활성화됐을 때만 my_func() 함수의 정의 자체를 컴파일에 포함시키고, 아니면 아예 없는 코드처럼 무시해버립니다.
마. #[inline] — 인라인 최적화 힌트
(1) 설명: 컴파일러에게 해당 함수를 인라인하도록 유도
(2) 예제:
#[inline(always)] fn fast_add(a: i32, b: i32) -> i32 { a + b }
fn main() { let x = add(3, 4); }
일반 호출: main에서 add 함수로 점프하고, 결과를 받아와서 x에 저장
인라인: 컴파일할 때 add(3, 4)를 그냥 3 + 4로 바꿔서 main 함수 안에 넣어버림
바. #[repr(…)] — 메모리 레이아웃 제어
(1) 설명: 구조체/열거형의 메모리 정렬 방법을 지정(repr은 representation(표현)의 약어)
(2) 종류:
C: C 언어와 동일한 레이아웃
packed: 패딩 없이 압축
transparent: 단일 필드 감싸기
(3) 예제:
#[repr(C)] struct MyStruct { a: u8, b: u32, }
사. #[non_exhaustive] — 미래 확장을 위한 열거형
(1) 설명: 나중에 항목이 더 생길 수 있으니, “지금 있는 것만 가지고 match를 완벽하게 쓰지 마세요“라는 의미입니다.
(2) 예제:
#[non_exhaustive] pub enum Error { Io, Parse, }
이 코드는 다음과 같은 의미를 가집니다.
Error enum은 지금은 Io와 Parse 두 가지 variant만 있지만, 앞으로 새로운 variant가 추가될 수 있으므로 다른 크레이트에서는 이 enum을 match할 때 지금 있는 것만으로 열거하지 못하게 제한하는 것입니다.
그래서 #[non_exhaustive]를 붙이면, 사용자는 반드시 _를 이용한 default arm을 추가해야만 컴파일이 가능하며, 이것은 다른 크레이트가 match를 지금 있는 것만으로 exhaustively(완전하게) 작성하면, 나중에 enum에 새로운 variant를 추가했을 때 컴파일이 깨질 수 있기 때문입니다.
위 코드는 important_result 함수의 반환 값을 사용하지 않아 warning(경고)이 발생하므로 아래와 같은 식으로 수정해야 합니다.
fn main() {
let result = important_result(); // OK
if let Err(e) = result {
println!("에러 발생: {}", e);
}
}
자. #[macro_use], #[macro_export] — 매크로 관련
(1) 설명: 외부 crate의 매크로를 가져오거나 내보낼 때 사용
(2) 예제:
// 외부 매크로 사용 #[macro_use] extern crate log;
// 매크로 정의 및 export #[macro_export] macro_rules! hello { () => { println!("Hello, macro!"); }; }
#[macro_use] : 외부 크레이트 log에서 정의된 매크로(log!, info!, warn! 등)들을 이 파일 안에서 직접 사용할 수 있도록 가져오라는 의미로서, 예전 Rust 스타일 (Rust 2018 이전)의 방식이며, 최신 Rust (2018 edition 이후)에서는 use log::info; 식으로 가져오는 게 일반적입니다.
#[macro_export] : 이 매크로를 다른 모듈/크레이트에서 사용할 수 있게 공개(export) 하겠다는 의미입니다. 따라서, 이 매크로를 crate_name::hello!() 식으로 다른 crate에서도 쓸 수 있습니다.
Rust에는 소유권, 참조, 라이프타임 등 고유한 용어들이 있는데 이외에도 생소하거나 중요한 용어인 variant, field, pattern, match arm, block, scope, associated type, attribute에 대해서 살펴 보겠습니다.
1. variant
정의: enum에서 각각의 경우(상태/종류)를 의미.
예시:
enum Color { Red, Blue, Green, } let c = Color::Red; // Red는 Color 타입의 variant
여기서 Red, Blue, Green이 각각 variant이다.
2. field
정의: struct(또는 enum의 variant)에 속하는 개별 데이터 항목.
예시:
struct Point { x: i32, // field y: i32, // field } let p = Point { x: 1, y: 2 };
x와 y가 각각 field이고, i32는 각각의 field의 타입(type of the field 또는 필드형/필드 타입)입니다.
enum Message { Quit, // 필드 없음 Move { x: i32, y: i32 }, // 필드 x, y가 있는 구조체 스타일 Write(String), // 이름 없는 튜플 스타일의 필드 String ChangeColor(i32, i32, i32), // 이름 없는 튜플 스타일의 필드 i32 }
Message enum의 variant가 갖는 값 또는 구조가 곧 해당 variant의 “필드”입니다. 구조체 스타일인 경우는 필드 개념이 동일하며, 튜플 형식인 경우는 구조체와 달리 필드가 없지만 값이 필드가 됩니다.
enum은 이 필드(데이터) 덕분에, variant별로 타입에 따라 다양한 정보를 유연하게 표현할 수 있습니다.
3. pattern
정의: 값을 구조적으로 분해 처리하기 위한 형태. match, let, 함수 매개 변수 등에서 사용합니다.
예시:
// struct Point 정의 struct Point { x: i32, y: i32, }
fn main() { // 튜플 패턴 예제 let (a, b) = (1, 2); println!("a = {}, b = {}", a, b);
// 구조체 및 구조체 패턴 매칭 예제 let p = Point { x: 10, y: 20 }; match p { Point { x, y } => println!("({}, {})", x, y), } }
패턴을 이용해 복잡한 데이터를 쉽게 분해할 수 있다.
let (a, b) = (1, 2); => 오른쪽 (1, 2)는 타입이 (i32, i32)인 튜플이며, 이 값을 튜플로 받아서, 첫 번째 요소는 변수 a에, 두 번째 요소는 변수 b에 바인딩해줘”라는 뜻입니다.
match p { Point { x, y } => println!(“({}, {})”, x, y), } 에서 Point { x, y }는 매칭 대상(p)이 해당 구조와 일치하는지 검사하고, 일치한다면 그 필드값을 변수로 분해해주는 패턴 역할을 합니다. 따라서 match에서 구조체 내부 값을 분해하고 싶으면 항상 이런 형태의 패턴을 사용하게 됩니다.
4. match arm
정의: match 구문의 각분기(패턴 + 처리 블록).
예시:
let n = 3; match n { 1 => println!("One"), // arm 1 2 | 3 | 5 => println!("Prime"), // arm 2 _ => println!("Other"), // arm 3 }
각각이 match arm이며, 패턴과 실행할 코드 블록으로 구성되어 있다.
match arm에서의 패턴(pattern)은, 매칭 대상이 되는 값이 어떤 구조나 값을 가지고 있는지 비교하고, 해당 구조와 일치하면 그 arm의 코드를 실행하도록 하는 역할을 합니다. 즉, match 구문의 각 arm(갈래, 분기)은 패턴 => 실행코드 형태로 이루어지며, 패턴은 값의 형태를 설명하거나 내부 값을 분해하는 구조입니다
4. block
정의: 중괄호 {}로 둘러싸인 코드 구역. 블록은 표현식이며 값과 타입을 가진다.
예시:
let result = { let x = 2; x * x // 마지막 표현식이 결과값이 됨 }; // result = 4
블록 내에서 선언된 변수는 해당 블록에서만 유효하다.
5. scope
정의: 변수나 아이템이 유효한 코드의 범위.
예시:
fn main() { let x = 10; // x는 main 함수 블록(scope)에서만 유효 }
scope이 끝나면 변수는 더 이상 쓸 수 없다.
가. block과 scope 비교
(1) block
코드에서 중괄호 {}로 둘러싸인 부분 자체를 block이라고 합니다.
예시:rust{ let a = 1; println!("{a}"); }
이 부분 전체가 block입니다.
(2) scope
scope는 어떤 변수(또는 아이템)를 ‘볼 수 있고 사용할 수 있는 코드의 범위’입니다.
scope는 보통 block에 의해 결정되지만, 완전히 같지는 않습니다.
모든 block은 새로운 scope를 열지만,
scope의 개념은 block 외에도 함수, 모듈, crate 등 더 넓거나 좁게 적용될 수 있습니다.
(3) 차이점 및 예제
block: { ... }로 감싸진 모든 코드 덩어리를 의미.
scope: 그 안에서 선언된 변수나 아이템이 유효한 코드의 범위.
모든 block이 scope를 정의하지만, scope는 더 넓은 개념입니다.
예시:
fn main() { // main 함수 block, 여기가 scope 시작 let outer = 10; // 'outer'의 scope는 main 함수 전체
{ // 새로운 block 시작, 이 안이 block scope let inner = 20; // 'inner'의 scope는 이 중괄호 안 println!("{}, {}", outer, inner); } // inner는 여기서 scope 종료