UTF-8은 가변 길이 문자 인코딩 방식으로, 각 문자의 유니코드 코드 포인트(Unicode code point)에 따라 1~4바이트를 사용합니다. 영어는 1바이트, 유럽계 언어는 2바이트, 한글, 일본어, 중국어 등을 포함한 대부분의 언어가 3바이트입니다.
1. UTF-8 바이트 수 규칙 요약
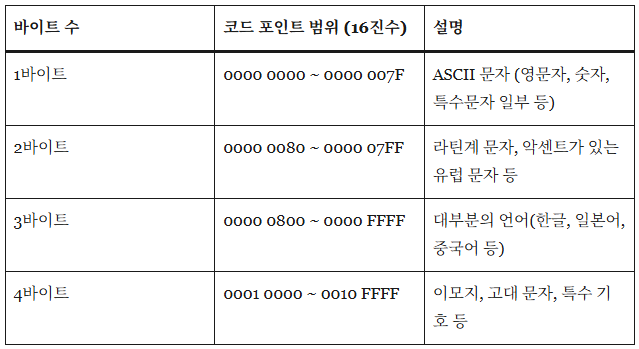
| 바이트 수 | 코드 포인트 범위 (16진수) | 설명 |
|---|
| 1바이트 | 0000 0000 ~ 0000 007F | ASCII 문자 (영문자, 숫자, 특수문자 일부 등) |
| 2바이트 | 0000 0080 ~ 0000 07FF | 라틴계 문자, 악센트가 있는 유럽 문자 등 |
| 3바이트 | 0000 0800 ~ 0000 FFFF | 대부분의 언어(한글, 일본어, 중국어 등) |
| 4바이트 | 0001 0000 ~ 0010 FFFF | 이모지, 고대 문자, 특수 기호 등 |
2. 언어별 문자 바이트 수 (UTF-8)
| 언어 | 평균 바이트 수 | 설명 |
|---|
| 영어 | 1바이트 | ASCII 문자 |
| 독일어/프랑스어 | 1~2바이트 | ñ, é, ü 같은 특수 라틴 문자는 2바이트 |
| 러시아어 (키릴 문자) | 2바이트 | 유니코드 범위 U+0400~U+04FF |
| 아랍어 | 2바이트 | U+0600~U+06FF |
| 히브리어 | 2바이트 | U+0590~U+05FF |
| 한글 (가/나/다 등 완성형) | 3바이트 | 한글 완성형(U+AC00~U+D7A3) |
| 일본어 (히라가나/가타카나/한자) | 3바이트 | 모든 문자 3바이트 |
| 중국어 (간체/번체) | 3바이트 | 일본어와 같은 한자 범위 사용 |
| 이모지 | 4바이트 | 😂, 🧡, 🐍 등 |
3. 예시
| 문자 | 언어 | UTF-8 인코딩 (hex) | 바이트 수 |
|---|
| A | 영어 | ox41 | 1바이트 |
| é | 프랑스어 | 0xC3A9 | 2바이트 |
| 한 | 한국어 | oxED959C | 3바이트 |
| 中 | 중국어 | 0xE4B8AD | 3바이트 |
| 😊 | 이모지 | 0xF09F988A | 4바이트 |
4. 정리
- 영어만 사용하는 텍스트가 가장 효율적 (1바이트/문자).
- 동아시아 문자(한중일)는 문자당 3바이트가 기본.
- 이모지나 일부 특수 기호는 4바이트를 차지하므로 저장공간이나 전송량에 유의.