자바(Java)는 모든 메소드를 클래스 내부에 정의합니다. 그러나, 러스트(Rust)는 데이터 구조(Struct)와 메소드(Impl block)가 물리적으로 분리되어 있습니다. 구조체 안에는 데이터만 정의하고, 별도의 impl 블록에서 그 구조체에 대한 메소드를 구현합니다.
Ⅰ. 데이터 구조, 메소드 구현 방식 비교
1. 자바: 클래스 내부에 메소드
자바(Java)는 모든 메소드를 클래스 내부에 정의합니다. 이는 객체 지향 프로그래밍(OOP)의 특징으로, 데이터(필드)와 행동(메소드)이 하나의 단위(클래스)에 밀접하게 결합(cohesion)되어 있습니다.
2. 러스트: 구조체와 메소드의 분리
러스트(Rust)에서는 데이터 구조(Struct)와 메소드(Impl block)가 물리적으로 분리되어 있습니다. 구조체 안에는 데이터만 정의하고, 별도의 impl 블록에서 그 구조체에 대한 메소드를 구현합니다.
3. 장단점
구분
자바(메소드=클래스 내부)
러스트(메소드=구조체 외부)
응집성
데이터와 행동이 하나에 묶임
데이터와 행동이 분리되어 명확
확장성
상속 등 OOP 구조 확장 용이
Trait, 여러 impl로 유연하게 확장
가독성
클래스 안에서 한 번에 파악 가능
데이터 정의와 메소드 구현 분리
유연성
하나의 클래스가 하나의 메소드 집합
같은 구조체에 여러 impl, trait 구현 가능
재사용성
상속, 인터페이스로 구현
Trait 등으로 다양한 방식의 재사용
관리의 용이성
대형 클래스에서 복잡해질 수 있음
관련 없는 메소드를 구조체와 별도 구현 가능
코드 조직화
OOP 방식(클래스-중심)
데이터 중심(struct), 행동 분리(impl, trait)
자바는 객체 중심의 응집력, 개발 및 이해 용이성이 강점이나, 큰 클래스가 복잡해지거나 상속 구조의 한계 등이 있습니다.
러스트는 데이터와 행동의 분리로 역할이 명확하며, trait 기반의 확장성과 안전성이 강점이지만, 초보자에겐 코드 연관성 파악이 다소 불편할 수 있습니다.
Ⅱ. 예제를 통한 비교
1. 자바(Java)
자바에서는 데이터(필드)와 메소드가 한 클래스 내부에 정의되어 객체 지향 프로그래밍 패러다임에 맞춰 응집되어 있습니다.
public class Point { private int x; private int y;
// 생성자 public Point(int x, int y) { this.x = x; this.y = y; }
// 메소드: 두 점 사이 거리 계산 public double distance(Point other) { int dx = this.x - other.x; int dy = this.y - other.y; return Math.sqrt(dx * dx + dy * dy); }
// getter 메소드 public int getX() { return x; } public int getY() { return y; } }
// 사용 public class Main { public static void main(String[] args) { Point p1 = new Point(0, 0); Point p2 = new Point(3, 4); System.out.println(p1.distance(p2)); // 출력: 5.0 } }
특징: Point 클래스 내부에 데이터(x, y)와 동작(거리 계산 메소드)을 모두 포함.
장점: 객체 지향적 응집성(cohesion) 강화, 한 곳에서 모든 관련 기능 파악 가능.
단점: 클래스가 커질수록 복잡성 증가, 상속 구조 제한 등.
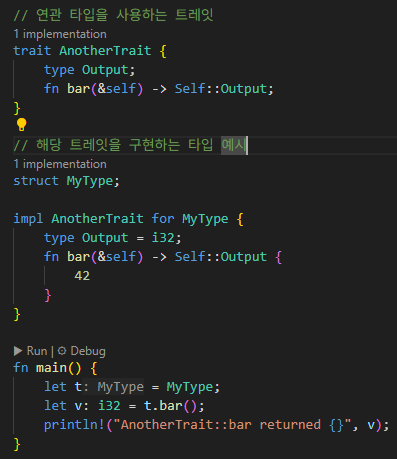
2. 러스트(Rust)
러스트는 데이터 구조체(struct)와 메소드 구현부(impl 블록)를 분리해서 작성합니다. 이로써 역할 분리가 명확해지고, 여러 impl 블록과 trait을 통해 유연하게 확장할 수 있습니다.
// 데이터 정의: 구조체는 필드만 가짐 struct Point { x: i32, y: i32, }
// 메소드 구현: impl 블록에서 정의 impl Point { // 연관 함수(정적 메서드와 유사) fn new(x: i32, y: i32) -> Point { Point { x, y } }
// 메소드: 두 점 사이 거리 계산 fn distance(&self, other: &Point) -> f64 { let dx = (self.x - other.x) as f64; let dy = (self.y - other.y) as f64; (dx.powi(2) + dy.powi(2)).sqrt() } }
fn main() { let p1 = Point::new(0, 0); let p2 = Point::new(3, 4); println!("{}", p1.distance(&p2)); // 출력: 5.0 }
특징: struct는 데이터만 선언, 메소드는 별도의 impl 블록에서 구현.
장점: 데이터와 행동이 분리되어 역할 명확, 여러 impl이나 trait로 기능 확장 유리, 컴파일타임 안전성 증대.
단점: 관련 데이터와 메소드가 코드상 분리되어 있어 한눈에 파악하기 어려울 수 있음, 전통적인 OOP 방식과 차이 있음.
3. 비교 표
항목
자바(Java)
러스트(Rust)
구조
클래스 내부에 데이터와 메소드가 함께 있음
구조체(데이터)와 impl 블록(메소드)로 분리
작성 방식
한 클래스 파일 내에서 모든 정의
struct로 데이터 정의, 별도 impl로 메소드 구현
확장성
상속과 인터페이스 기반 확장 (단일 상속)
여러 impl 블록과 trait 조합으로 유연하고 다중 확장 가능
가독성
관련 데이터와 메소드가 한 곳에 있어 파악 용이
데이터와 메소드가 분리되어 코드가 흩어질 수 있음
안전성
런타임 검사 및 가비지 컬렉션
컴파일 타임 소유권 및 빌림 검사로 메모리 안전성 강화
메모리
참조 타입 중심, 힙 할당 및 가비지 컬렉션 필요
값 타입 중심, 명확한 메모리 제어 및 성능 최적화 가능
객체 지향
전통적인 OOP 완전 지원
클래스는 없으나 trait로 인터페이스 역할 및 객체지향 유사 기능 제공
러스트의 구조체+impl 방식은 자바와는 다르게 데이터와 메소드가 분리되어 있지만, impl 블록 내에서 메소드를 묶어 객체 지향적 프로그래밍의 많은 특징을 흉내 낼 수 있습니다. trait를 활용하면 인터페이스 역할도 하며, 상속 대신 다중 trait 구현으로 유연하게 기능을 확장할 수 있습니다.
Ⅲ . 자바의 상속과 인터페이스 구조와 러스트의 고급 Trait(트레이트) 및 패턴 비교
자바의 상속과 인터페이스 구조와 러스트의 고급 Trait(트레이트) 및 패턴을 심도 있게 비교 설명하면 다음과 같습니다.
1. 자바의 상속과 인터페이스 구조
가. 상속 (Inheritance)
클래스 간에 “is-a” 관계를 표현하는 가장 기본적인 메커니즘입니다.
한 클래스가 다른 클래스(부모 클래스)를 상속받아 멤버 변수와 메소드를 재사용하거나 오버라이드할 수 있습니다.
단일 상속만 지원하여 다중 상속의 복잡성을 회피합니다.
상속 구조가 깊어지면 유지보수가 어려워지고, 부모 클래스 변경 시 자식 클래스에 의도치 않은 영향이 발생할 수 있음.
나. 인터페이스 (Interface)
여러 클래스가 구현해야 하는 메소드의 명세(계약)를 정의합니다.
자바 8부터는 디폴트 메소드 구현도 지원하여 일부 기능적 확장 가능.
인터페이스의 다중 구현이 가능해 상속 단점을 보완하고 다형성 제공.
인터페이스는 구현 메소드가 없거나 기본 구현만 제공하므로, 설계 시 유연성을 줌.
interface Flyer { void fly(); } class Bird implements Flyer { public void fly() { System.out.println("Bird is flying"); } } class Airplane implements Flyer { public void fly() { System.out.println("Airplane is flying"); } }
2. 러스트의 고급 Trait 및 패턴
가. Trait(트레이트) 개념
러스트의 트레이트는 특정 기능을 구현하도록 강제하는 인터페이스 역할을 합니다.
타입에 따라 여러 트레이트를 다중으로 구현할 수 있어 매우 유연합니다.
트레이트 내에 메소드 기본 구현(default method)을 제공해 부분 구현도 가능.
Trait는 다중 상속을 대체하며, 조합(composition) 및 다형성을 지원합니다.
나. 고급 트레이트 특징
(1) 동일 메소드명을 가진 다중 트레이트 구현 (충돌 해결)
예를 들어, 같은 이름 fly() 메소드를 가진 서로 다른 트레이트 Pilot, Wizard를 Human 타입에 모두 구현 가능.
호출 시 Pilot::fly(&human), Wizard::fly(&human)처럼 트레이트 이름을 명시해 충돌 해결.
fn main() { let person = Human; Pilot::fly(&person); // This is your captain speaking. Wizard::fly(&person); // Up! person.fly(); // *waving arms furiously* }
(2) 슈퍼 트레이트 (Super-traits)
한 트레이트가 다른 트레이트의 구현을 전제로 하는 경우 사용.
예: OutlinePrint 트레이트가 Display 트레이트를 반드시 구현한 경우에만 구현 가능하도록 제한.
use std::fmt::Display;
trait OutlinePrint: Display { fn outline_print(&self) { // Display 기능 이용해 출력하는 구현 println!("*{}*", self); } }
(3) 제네릭과 트레이트 바운드 (Trait Bounds)
함수, 구조체, 열거형 등에서 트레이트를 타입 매개변수 조건으로 지정하여 유연한 재사용성 제공.
Rust에서 variable binding(변수 바인딩)은 값을 변수 이름에 연결하는 과정을 의미하며, Rust 프로그래밍에서 변수 선언과 관련된 기본 개념입니다. Rust는 정적 타입 언어이고 기본적으로 변수가 불변(immutable)으로 선언되기에, 가변성을 가지려면 일부러 명시해야 합니다. 이와 함께 Rust의 바인딩은 shadowing(변수 가리기)이나 스코프와 밀접하게 연관되어 있어, 변수 활용 시 중요한 개념입니다.
Ⅰ. 기본 자료형(Primitive Type)
1. 변수 바인딩 기본
Rust에서 변수 바인딩은 let 키워드로 선언합니다. 이때 변수는 기본적으로 불변입니다. 따라서 선언 후 값을 변경하려 하면 컴파일 에러가 발생합니다.
fn main() { let x = 5; println!("x의 값: {}", x); // x = 6; // 오류: 불변 변수에 재할당 불가 }
이 코드는 x를 5로 바인딩했지만, 이후 x = 6과 같이 변경하려 하면 컴파일 에러가 발생합니다. Rust 컴파일러는 이런 불변 변수 변경 시도를 막아 안정성을 보장합니다.
2. 가변 변수 (Mutable Binding)
변수를 변경 가능하게 하려면 mut 키워드를 사용해 가변 변수로 선언해야 합니다.
fn main() { let mut x = 5; println!("초기 x: {}", x); x = 6; println!("변경된 x: {}", x); }
이렇게 하면 x에 대한 값 변경이 가능해집니다. 컴파일러가 에러 발생 시 mut를 추가하라고 친절히 안내하는 점도 Rust의 특징입니다.
3. 타입 추론 및 명시적 타입 선언
Rust 컴파일러는 대부분의 경우 변수 선언 시 타입을 자동 추론합니다.
let x = 42; // i32로 추론 let y = true; // bool로 추론 let z: u32 = 10; // 명시적 타입 선언
필요에 따라 타입을 명시할 수도 있지만, 대부분 타입 추론에 맡깁니다.
4. 변수 가리기 (Shadowing)
Rust의 독특한 특징인 변수 가리기는 같은 이름의 변수를 같은 스코프 내에서 다시 let으로 선언하여 새 변수를 만드는 것입니다. 이때 이전 변수는 새 변수에 의해 가려집니다.
fn main() { let x = 5; let x = x + 1; // 이전 x를 가리고 새 x 선언 { let x = x * 2; println!("내부 스코프의 x: {}", x); // 12 } println!("외부 스코프의 x: {}", x); // 6 }
위 예제에서 첫 번째 x는 5, 두 번째는 6, 내부 스코프의 x는 12입니다. 이렇게 하면 가변 변수 없이도 값 변경 효과를 낼 수 있고 타입도 변경할 수 있습니다.
5. 스코프와 변수 유효 범위
변수는 선언된 블록 {} 내에서만 유효하며, 블록을 벗어나면 사라집니다.
fn main() { let x = 1; { let y = 2; println!("내부 스코프 y: {}", y); // 2 } // println!("외부 스코프 y: {}", y); // 오류: y는 유효하지 않음 }
또한 내부 스코프에서 같은 이름으로 변수를 다시 선언하면 외부 변수를 가립니다.
6. 실습 예제 종합
fn main() { // 불변 변수 let a = 10; println!("a: {}", a); // a = 20; // 컴파일 에러!
// 가변 변수 let mut b = 10; println!("b 초기값: {}", b); b = 20; println!("b 변경 후: {}", b);
// 변수 가리기 (shadowing) let c = 5; let c = c + 10; // 이전 c 가리기, 이제 c = 15 println!("c: {}", c);
{ let c = c * 2; // 내부 스코프 가리기, c = 30 println!("내부 블록의 c: {}", c); }
println!("외부 블록의 c: {}", c);
// 타입 변경이 가능한 shadowing let d = "문자열"; println!("d는 문자열: {}", d); let d = d.len(); // 같은 이름 변수에 정수 대입 (shadowing) println!("d는 문자열 길이: {}", d); }
출력 결과:
a: 10 b 초기값: 10 b 변경 후: 20 c: 15 내부 블록의 c: 30 외부 블록의 c: 15 d는 문자열: 문자열 d는 문자열 길이: 6
Ⅱ. 벡터(Vector)와 튜플(Tuple) 타입 변수 바인딩
1. 벡터(Vector) 타입 변수 바인딩
벡터는 같은 타입 요소들을 동적 크기로 저장하는 컬렉션입니다. Rust에서 벡터는 Vec<T> 타입으로 표현됩니다.
벡터 바인딩 기본 예:
fn main() { // 빈 vector 생성 (타입 명시 필요) let mut v: Vec<i32> = Vec::new(); // 값 추가 가능하려면 mut 필요 v.push(1); v.push(2); println!("{:?}", v); // 출력: [1, 2]
// 초기값과 함께 벡터 생성 (타입 추론 가능) let v2 = vec![10, 20, 30]; println!("{:?}", v2); // 출력: [10, 20, 30] }
벡터의 요소 접근:
let first = v2[0]; // 인덱스를 통한 접근 (주의: 범위 초과 시 패닉) let maybe_first = v2.get(0); // Option 타입 반환 (안전 접근)
가변 벡터 요소 수정도 mut으로 가능:
let mut v3 = vec![1, 2, 3]; v3[1] = 5; // 두 번째 요소를 5로 변경
벡터는 가변성을 가지고 가리키는 데이터가 동적으로 바뀔 수 있으므로 보통 mut 바인딩과 함께 선언합니다.
2. 3차원 벡터
1) 가변 크기: Vec<Vec<Vec<T>>>
// 2 x 3 x 4 크기의 0으로 채워진 3차원 벡터 let x = 2; let y = 3; let z = 4; let mut v: Vec<Vec<Vec<i32>>> = vec![vec![vec![0; z]; y]; x];
// 값 접근 let team_name = String::from("Blue"); let score = scores.get(&team_name).copied().unwrap_or(0);
println!("Blue 팀 점수: {}", score);
// 해시맵의 모든 키-값 쌍 출력 for (key, value) in &scores { println!("{key}: {value}"); } }
여기서 scores 변수에 해시맵 데이터 구조가 바인딩되었고,
mut 키워드 때문에 값 삽입과 변경이 가능합니다.
.insert() 메서드로 키-값 쌍을 추가하거나 갱신하며,
.get() 메서드로 해당 키에 연관된 값을 읽을 수 있습니다.
요약하면, 해시맵도 배열, 벡터, 튜플, 구조체와 같이 Rust에서 변수 바인딩 개념이 동일하게 적용됩니다. let으로 이름을 데이터에 바인딩하고, 변경하려면 mut가 필수입니다. 해시맵은 키-값 쌍 컬렉션이라는 점에서 특수하지만, 바인딩이라는 개념 면에서는 일반 변수와 차이가 없습니다.
추가적으로 해시맵 내부에 구조체 같은 복합 데이터 타입을 저장해도, 변수 바인딩과 관련된 기본 원칙은 같습니다.
Ⅴ. 사용자 정의 타입
Rust에서 사용자 정의 타입(예: 구조체와 열거형)에 대한 변수 바인딩은 기본 타입이나 벡터, 튜플 등과 동일하게 let 키워드를 사용하여 값을 변수 이름에 연결하는 것을 의미합니다. 하지만 구조체와 열거형은 내부 필드나 variant에 데이터를 포함할 수 있어서, 변수 바인딩과 활용이 더 다양한 형태로 나타납니다.
아래에서 구조체와 열거형을 사용자 정의 타입의 변수 바인딩 예제로 구체적으로 설명합니다.
1. 구조체(Struct) 변수 바인딩 예제
// 구조체 정의 struct Point { x: i32, y: i32, }
fn main() { // 구조체 인스턴스를 생성하고 변수 p에 바인딩 let p = Point { x: 10, y: 20 };
// 구조체 필드에 접근 println!("x: {}, y: {}", p.x, p.y);
// 가변 바인딩 시 필드 값 변경 가능 let mut p_mut = Point { x: 5, y: 5 }; p_mut.x = 15; println!("변경된 x: {}", p_mut.x);
// 구조체를 분해하여 필드 값을 각각 변수에 바인딩 let Point { x: a, y: b } = p; println!("분해된 x: {}, y: {}", a, b); }
let p = Point { … };에서 p는 Point 타입 값에 변수 바인딩입니다.
패턴 매칭처럼 let Point { x: a, y: b } = p; 구문으로 구조체 필드를 변수 a, b에 바인딩할 수도 있습니다.
mut 키워드로 가변 바인딩을 선언하면 구조체 필드를 수정할 수 있습니다.
2. 열거형(Enum) 변수 바인딩 예제
// 열거형 정의 enum Message { Quit, // 데이터 없는 variant Move { x: i32, y: i32 }, // 필드가 있는 variant (struct-like) Write(String), // 튜플 형태 variant ChangeColor(i32, i32, i32), // 여러 필드를 가진 튜플 variant }
fn main() { // enum 값에 변수 바인딩 let msg = Message::Move { x: 10, y: 20 };
// match로 variant별 데이터 바인딩과 처리 match msg { Message::Quit => println!("Quit variant"), Message::Move { x, y } => println!("Move to x: {}, y: {}", x, y), Message::Write(text) => println!("Write message: {}", text), Message::ChangeColor(r, g, b) => println!("Change color to {}, {}, {}", r, g, b), } }
Rust의 동시성(concurrency)은 안전성과 성능을 모두 고려한 설계로, 데이터 경쟁(data race)을 컴파일 타임에 방지하고, 성능 저하 없이 병렬 처리를 가능하게 합니다. C++, Java, Python, Go 등 타 언어와 비교해 장단점을 알아보겠습니다.
1. Rust의 동시성 개념
Rust는 동시성을 다음 세 가지 방식으로 지원합니다:
스레드 기반 동시성 (std::thread)
OS 스레드를 생성하여 병렬 작업 수행.
thread:spawn을 통해 새로운 스레드를 실행.
메시지 기반 통신 (std::sync::mpsc)
채널을 통해 스레드 간 데이터 교환.
데이터 소유권을 안전하게 이동.
비동기 프로그래밍 (async/await, tokio, async-std)
효율적인 I/O 처리.
싱글 스레드에서 수천 개의 작업을 동시에 처리할 수 있음.
Future를이용한 논블로킹 방식.
2. Rust 동시성의 핵심 특징
특징
설명
데이터 레이스 방지
컴파일 타임에 mut, &mut, Send, Sync 등을 통해 공유 자원에 대한 안전성 확보
제로 코스트 추상화
고급 추상화를 사용해도 런타임 오버헤드 없음
fearless concurrency
안전하게 동시성을 구현할 수 있어 “두려움 없는 동시성”이라고도 불림
3. 타 언어와의 비교
가. Rust vs C++
항목
Rust
C++
안전성
컴파일 타임 데이터 레이스 방지
런타임에서 버그 발견 가능
메모리 모델
소유권 시스템
수동 메모리 관리
쓰레드 API
안전하고 모던한 추상화
복잡하고 안전하지 않은 경우 많음
🔹 Rust는 안전하고 버그 없는 병렬 처리를 제공 🔸 C++은 성능은 뛰어나지만 관리 책임이 개발자에게 있음 (예: 뮤텍스 실수 → 데이터 손상)
나. Rust vs Java
항목
Rust
Java
런타임
없음 (네이티브 실행)
JVM 기반
동기화
Mutex, RwLock, channel 등 명시적
synchronized, volatile, ExecutorService 등
성능
시스템 수준 고성능
GC와 JVM 오버헤드 존재
🔹 Rust는 GC 없는 고성능 동시성 🔸 Java는 GC로 메모리 관리가 쉽지만 지연 가능성 존재
다. Rust vs Python
항목
Rust
Python
성능
매우 빠름
느림 (인터프리터 기반)
GIL (Global Interpreter Lock)
없음
있음 (멀티 코어 병렬 처리 불가)
비동기 처리
고성능 async/await
asyncio로 가능하나 성능은 낮음
🔹 Rust는 진짜 병렬 처리 가능 🔸 Python은 GIL 때문에 CPU 병렬처리에 약함 (I/O 병렬만 현실적)
라. 요약
구분
Rust의 장점
Rust의 단점
성능
네이티브 수준의 성능
안전성을 위한 빌드 시간 증가
안전성
데이터 레이스를 컴파일 타임에 방지
초기 진입 장벽 (개념이 복잡함)
표현력
async/await, channel, Mutex 등 현대적 추상화
도구/라이브러리 생태계가 다른 언어보다 적은 편
병렬성
GIL 없음, 진짜 병렬 처리 가능
쓰레드 디버깅이 어려울 수 있음
4. Rust 동시성이 특히 유리한 분야
고성능 웹 서버 (예: Actix, Axum)
실시간 시스템 (예: 게임, IoT)
병렬 데이터 처리 (예: 이미지/영상 처리)
시스템 프로그래밍 (드라이버, 임베디드)
5. 1부터 100만까지 숫자의 합을 4개 스레드로 나눠 병렬 계산 비교
가. Rust 버전
use std::thread;
fn main() { let data: Vec<u64> = (1..=1_000_000).collect(); let chunk_size = data.len() / 4;
let mut handles = vec![];
for i in 0..4 { let chunk = data[i * chunk_size..(i + 1) * chunk_size].to_vec(); let handle = thread::spawn(move || chunk.iter().sum::<u64>()); handles.push(handle); }
let total: u64 = handles.into_iter().map(|h| h.join().unwrap()).sum(); println!("합계: {}", total); }
✅ 설명:
use std::thread;
Rust의 표준 라이브러리에서 thread 모듈을 가져옵니다. 병렬 처리를 위해 사용됩니다.
let data: Vec<u64> = (1..=1_000_000).collect();
(1..=1_000_000)는 표현식이며 RangeInclusive 타입으로, 1부터 1_000_000까지 포함하는 이터레이터입니다.
.collect()는 이터레이터(iterator)를 모아서 컬렉션(예: Vec, HashMap, String)으로 변환하는 메서드입니다.
명시적으로 Vec 타입을 선언했기 때문에, collect()는 모든 숫자를 벡터로 수집하게 됩니다.
let chunk_size = data.len() / 4;
데이터를 4개의 스레드로 나눌 것이기 때문에, 각 스레드가 처리할 데이터의 크기를 계산합니다.
chunk_size = 250_000
let mut handles = vec![];
스레드 핸들(JoinHandle)들을 저장할 벡터.
각 스레드는 나중에 .join()으로 결과를 수집할 수 있습니다.
for i in 0..4 { let chunk = data[i * chunk_size..(i + 1) * chunk_size].to_vec(); let handle = thread::spawn(move || chunk.iter().sum::<u64>()); handles.push(handle); }
루프를 4번 돌며 벡터를 4등분합니다.
let chunk = data[i * chunk_size..(i + 1) * chunk_size].to_vec();
data를 4등분하여 각 스레드에 넘길 복사본을 만든 후 chunk에 할당합니다.
i가 0~3까지 반복되므로:
i = 0 일 때는 data[0..250000]
i = 1 일 때는 data[250000..500000]
i = 2 일 때는 data[500000..750000]
i = 3 일 때는 data[750000..1000000]
이렇게 전체 데이터를 4개의 슬라이스(slice)로 나눕니다. 하지만 슬라이스는 참조(&)이며, 여러 스레드가 같은 데이터를 공유할 때, 데이터 경합(data race)을 막기 위해 컴파일러가 참조의 안전성을 보장해야 하므로, .to_vec()을 사용하여 슬라이스의 복사본을 만들어 소유권을 가지는 새 벡터로 만듭니다. 이제 이 벡터는 독립적 소유권을 가지므로, move를 통해 클로저에 안전하게 넘길 수 있습니다
let handle = thread::spawn(move || chunk.iter().sum::<u64>());
thread::spawn(…) → 새로운 스레드(thread)를 만들어서 주어진 작업을 실행합니다.
move || … → 클로저(익명 함수)에서 외부 변수인 chunk의 소유권을 이동시켜 사용합니다.
chunk.iter().sum::() → chunk의 모든 원소를 합산하여 u64값을 반환합니다.
반환된 handle은 JoinHandle 타입이고, 이걸 handles 벡터에 저장해 나중에 결과를 수집합니다.
let total: u64 = handles.into_iter().map(|h| h.join().unwrap()).sum();
스레드에서 계산한 4개의 부분합을 모아서 전체 합을 계산한다.
handles.into_iter() .into_iter()는 handles 벡터의 소유권을 consuming iterator로 가져옵니다(copy가 아닌 move). 즉, 이후 handles는 더 이상 사용할 수 없습니다.
.map(|h| h.join().unwrap())의각 h는 JoinHandle 이고, h.join()은 이 스레드가 끝날 때까지 기다리고, .unwrap()으로 에러 무시하고 강제 추출합니다. .map(…) 부분은 4개의 스레드를 기다리며 각각의 계산된 합을 모아 [u64; 4] 형태로 만듭니다
.sum()은 [u64; 4]을 전부 더해서 최종 합계를 구해서, total에 할당합니다.
data = list(range(1, 1_000_001)) results = [0] * 4
def worker(idx, chunk): results[idx] = sum(chunk)
threads = [] chunk_size = len(data) // 4
for i in range(4): t = threading.Thread(target=worker, args=(i, data[i*chunk_size:(i+1)*chunk_size])) threads.append(t) t.start()
for t in threads: t.join()
print("합계:", sum(results))
🔸 설명:
Python은 GIL(Global Interpreter Lock) 때문에 진짜 병렬 아님
threading은 CPU 병렬 처리 불가 → 오히려 느림
multiprocessing을 쓰면 병렬 가능하지만 복잡도 증가
다. Java 버전
import java.util.concurrent.*;
public class Main { public static void main(String[] args) throws InterruptedException, ExecutionException { ExecutorService executor = Executors.newFixedThreadPool(4); int[] data = new int[1_000_000]; for (int i = 0; i < data.length; i++) data[i] = i + 1;
Future<Long>[] results = new Future[4]; int chunkSize = data.length / 4;
for (int i = 0; i < 4; i++) { final int start = i * chunkSize; final int end = (i + 1) * chunkSize; results[i] = executor.submit(() -> { long sum = 0; for (int j = start; j < end; j++) sum += data[j]; return sum; }); }
long total = 0; for (Future<Long> result : results) { total += result.get(); }
Rust에서의 attribute(속성)는 컴파일러에게 특정 코드에 대한 추가적인 정보를 제공하여, 코드의 컴파일 방식 또는 동작 방식을 제어하거나, 경고/에러 메시지를 제어하는 데 사용됩니다. derive, allow, warn, cfg, test 등 다양한 종류가 있습니다.
1. attribute의 적용 범위별 종류
Rust의 attribute는 크게 다음과 같은 종류로 나눌 수 있습니다:
종류
형태 예시
설명
Item attribute
#[derive(Debug)]
함수, 구조체 등 개별 항목에 적용
Crate attribute
#![allow(dead_code)]
크레이트 전체에 적용, 보통 파일 상단에 위치
Inner attribute
#![cfg(test)]
모듈 또는 크레이트 내부에 선언, 내부 항목에 영향을 줌
Outer attribute
#[test]
특정 항목(함수 등)에만 적용
2. 주요 attribute
가. 컴파일러 관련 attribute
Attribute
설명
예시
#[allow(…)]
특정 경고를 무시
#[allow(dead_code)]
#[warn(…)]
경고를 표시 (기본값)
#[warn(unused_variables)]
#[deny(…)]
해당 사항이 있으면 컴파일 에러
#[deny(missing_docs)]
#[forbid(…)]
deny보다 강하게 재정의 불가
#[forbid(unsafe_code)]
나. 파생(derive) 관련 attribute
Rust의 많은 기능은 trait을 자동으로 구현해주는 #[derive(…)]를 통해 사용합니다.
“my_feature”라는 기능(feature)이 활성화됐을 때만 my_func() 함수의 정의 자체를 컴파일에 포함시키고, 아니면 아예 없는 코드처럼 무시해버립니다.
마. #[inline] — 인라인 최적화 힌트
(1) 설명: 컴파일러에게 해당 함수를 인라인하도록 유도
(2) 예제:
#[inline(always)] fn fast_add(a: i32, b: i32) -> i32 { a + b }
fn main() { let x = add(3, 4); }
일반 호출: main에서 add 함수로 점프하고, 결과를 받아와서 x에 저장
인라인: 컴파일할 때 add(3, 4)를 그냥 3 + 4로 바꿔서 main 함수 안에 넣어버림
바. #[repr(…)] — 메모리 레이아웃 제어
(1) 설명: 구조체/열거형의 메모리 정렬 방법을 지정(repr은 representation(표현)의 약어)
(2) 종류:
C: C 언어와 동일한 레이아웃
packed: 패딩 없이 압축
transparent: 단일 필드 감싸기
(3) 예제:
#[repr(C)] struct MyStruct { a: u8, b: u32, }
사. #[non_exhaustive] — 미래 확장을 위한 열거형
(1) 설명: 나중에 항목이 더 생길 수 있으니, “지금 있는 것만 가지고 match를 완벽하게 쓰지 마세요“라는 의미입니다.
(2) 예제:
#[non_exhaustive] pub enum Error { Io, Parse, }
이 코드는 다음과 같은 의미를 가집니다.
Error enum은 지금은 Io와 Parse 두 가지 variant만 있지만, 앞으로 새로운 variant가 추가될 수 있으므로 다른 크레이트에서는 이 enum을 match할 때 지금 있는 것만으로 열거하지 못하게 제한하는 것입니다.
그래서 #[non_exhaustive]를 붙이면, 사용자는 반드시 _를 이용한 default arm을 추가해야만 컴파일이 가능하며, 이것은 다른 크레이트가 match를 지금 있는 것만으로 exhaustively(완전하게) 작성하면, 나중에 enum에 새로운 variant를 추가했을 때 컴파일이 깨질 수 있기 때문입니다.
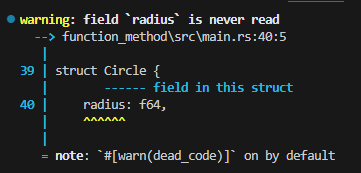
위 코드는 important_result 함수의 반환 값을 사용하지 않아 warning(경고)이 발생하므로 아래와 같은 식으로 수정해야 합니다.
fn main() {
let result = important_result(); // OK
if let Err(e) = result {
println!("에러 발생: {}", e);
}
}
자. #[macro_use], #[macro_export] — 매크로 관련
(1) 설명: 외부 crate의 매크로를 가져오거나 내보낼 때 사용
(2) 예제:
// 외부 매크로 사용 #[macro_use] extern crate log;
// 매크로 정의 및 export #[macro_export] macro_rules! hello { () => { println!("Hello, macro!"); }; }
#[macro_use] : 외부 크레이트 log에서 정의된 매크로(log!, info!, warn! 등)들을 이 파일 안에서 직접 사용할 수 있도록 가져오라는 의미로서, 예전 Rust 스타일 (Rust 2018 이전)의 방식이며, 최신 Rust (2018 edition 이후)에서는 use log::info; 식으로 가져오는 게 일반적입니다.
#[macro_export] : 이 매크로를 다른 모듈/크레이트에서 사용할 수 있게 공개(export) 하겠다는 의미입니다. 따라서, 이 매크로를 crate_name::hello!() 식으로 다른 crate에서도 쓸 수 있습니다.
Rust에는 소유권, 참조, 라이프타임 등 고유한 용어들이 있는데 이외에도 생소하거나 중요한 용어인 variant, field, pattern, match arm, block, scope, associated type, attribute에 대해서 살펴 보겠습니다.
1. variant
정의: enum에서 각각의 경우(상태/종류)를 의미.
예시:
enum Color { Red, Blue, Green, } let c = Color::Red; // Red는 Color 타입의 variant
여기서 Red, Blue, Green이 각각 variant이다.
2. field
정의: struct(또는 enum의 variant)에 속하는 개별 데이터 항목.
예시:
struct Point { x: i32, // field y: i32, // field } let p = Point { x: 1, y: 2 };
x와 y가 각각 field이고, i32는 각각의 field의 타입(type of the field 또는 필드형/필드 타입)입니다.
enum Message { Quit, // 필드 없음 Move { x: i32, y: i32 }, // 필드 x, y가 있는 구조체 스타일 Write(String), // 이름 없는 튜플 스타일의 필드 String ChangeColor(i32, i32, i32), // 이름 없는 튜플 스타일의 필드 i32 }
Message enum의 variant가 갖는 값 또는 구조가 곧 해당 variant의 “필드”입니다. 구조체 스타일인 경우는 필드 개념이 동일하며, 튜플 형식인 경우는 구조체와 달리 필드가 없지만 값이 필드가 됩니다.
enum은 이 필드(데이터) 덕분에, variant별로 타입에 따라 다양한 정보를 유연하게 표현할 수 있습니다.
3. pattern
정의: 값을 구조적으로 분해 처리하기 위한 형태. match, let, 함수 매개 변수 등에서 사용합니다.
예시:
// struct Point 정의 struct Point { x: i32, y: i32, }
fn main() { // 튜플 패턴 예제 let (a, b) = (1, 2); println!("a = {}, b = {}", a, b);
// 구조체 및 구조체 패턴 매칭 예제 let p = Point { x: 10, y: 20 }; match p { Point { x, y } => println!("({}, {})", x, y), } }
패턴을 이용해 복잡한 데이터를 쉽게 분해할 수 있다.
let (a, b) = (1, 2); => 오른쪽 (1, 2)는 타입이 (i32, i32)인 튜플이며, 이 값을 튜플로 받아서, 첫 번째 요소는 변수 a에, 두 번째 요소는 변수 b에 바인딩해줘”라는 뜻입니다.
match p { Point { x, y } => println!(“({}, {})”, x, y), } 에서 Point { x, y }는 매칭 대상(p)이 해당 구조와 일치하는지 검사하고, 일치한다면 그 필드값을 변수로 분해해주는 패턴 역할을 합니다. 따라서 match에서 구조체 내부 값을 분해하고 싶으면 항상 이런 형태의 패턴을 사용하게 됩니다.
4. match arm
정의: match 구문의 각분기(패턴 + 처리 블록).
예시:
let n = 3; match n { 1 => println!("One"), // arm 1 2 | 3 | 5 => println!("Prime"), // arm 2 _ => println!("Other"), // arm 3 }
각각이 match arm이며, 패턴과 실행할 코드 블록으로 구성되어 있다.
match arm에서의 패턴(pattern)은, 매칭 대상이 되는 값이 어떤 구조나 값을 가지고 있는지 비교하고, 해당 구조와 일치하면 그 arm의 코드를 실행하도록 하는 역할을 합니다. 즉, match 구문의 각 arm(갈래, 분기)은 패턴 => 실행코드 형태로 이루어지며, 패턴은 값의 형태를 설명하거나 내부 값을 분해하는 구조입니다
4. block
정의: 중괄호 {}로 둘러싸인 코드 구역. 블록은 표현식이며 값과 타입을 가진다.
예시:
let result = { let x = 2; x * x // 마지막 표현식이 결과값이 됨 }; // result = 4
블록 내에서 선언된 변수는 해당 블록에서만 유효하다.
5. scope
정의: 변수나 아이템이 유효한 코드의 범위.
예시:
fn main() { let x = 10; // x는 main 함수 블록(scope)에서만 유효 }
scope이 끝나면 변수는 더 이상 쓸 수 없다.
가. block과 scope 비교
(1) block
코드에서 중괄호 {}로 둘러싸인 부분 자체를 block이라고 합니다.
예시:rust{ let a = 1; println!("{a}"); }
이 부분 전체가 block입니다.
(2) scope
scope는 어떤 변수(또는 아이템)를 ‘볼 수 있고 사용할 수 있는 코드의 범위’입니다.
scope는 보통 block에 의해 결정되지만, 완전히 같지는 않습니다.
모든 block은 새로운 scope를 열지만,
scope의 개념은 block 외에도 함수, 모듈, crate 등 더 넓거나 좁게 적용될 수 있습니다.
(3) 차이점 및 예제
block: { ... }로 감싸진 모든 코드 덩어리를 의미.
scope: 그 안에서 선언된 변수나 아이템이 유효한 코드의 범위.
모든 block이 scope를 정의하지만, scope는 더 넓은 개념입니다.
예시:
fn main() { // main 함수 block, 여기가 scope 시작 let outer = 10; // 'outer'의 scope는 main 함수 전체
{ // 새로운 block 시작, 이 안이 block scope let inner = 20; // 'inner'의 scope는 이 중괄호 안 println!("{}, {}", outer, inner); } // inner는 여기서 scope 종료
Rust의 기호(=>, ::, ., -> 등)와 연산자(산술, 비교, 사칙연산자, 논리 연산자, 패턴 매치 연산자 등) 는 종류도 많고 다른 언어와 다른 것도 있어 많이 헷갈리므로 이것에 대해 전체적으로 알아보겠습니다.
Ⅰ. 기호
1. =>
match 문에서 패턴 매핑 결과를 지정할 때 사용합니다.
let num = 2; match num { 1 => println!("one"), 2 => println!("two"), _ => println!("other"), }
위에서 2 => println!(“two”)는 num이 2일 때 실행됩니다.
2. ::
경로(네임스페이스) 구분자. 모듈, 구조체, 열거형, 연관함수, 상수 등에 접근할 때 사용합니다.
let color = Color::Red; let s = String::from("hello");
Color 열거형의 Red variant, String 타입의 from 연관 함수에 접근합니다.
3. .
필드 접근하거나 메서드를 호출할 때 사용합니다.
let s = String::from("hi"); let len = s.len(); // 메서드 호출 let point = (3, 4); let x = point.0; // 튜플의 첫 번째 요소
s.len()은 s 객체의 len 메서드를, point.0은 튜플의 첫번째 값을 뜻합니다.
4. ->
함수 또는 클로저의 반환 타입을 지정할 때 사용합니다.
fn add_one(x: i32) -> i32 { x + 1 }
이 함수는 매개변수 x를 받아 i32 타입으로 결과를 반환합니다.
5. :
변수의 타입을 명시하거나 패턴 매칭에서 사용됩니다.
let score: i32 = 100;
변수 score의 타입이 i32임을 명시합니다.
아래는 패턴 매칭에서 :이 사용된 예입니다. Point { x, y: 0 }에서 y: 0은 y 필드가 정확히 0일 때 매칭됨을 의미합니다.
struct Point { x: i32, y: i32 }
fn main() { let p = Point { x: 0, y: 7 }; match p { Point { x, y: 0 } => println!("On the x axis at {x}"), Point { x: 0, y } => println!("On the y axis at {y}"), Point { x, y } => println!("On neither axis: ({x}, {y})"), } }
6. ;
구문(문장)의 끝을 표시합니다.
let x = 5; println!("{}", x);
7. ,
목록(튜플, 인수 등)을 구분할 때 사용합니다.
rustlet point = (3, 4); fn add(x: i32, y: i32) -> i32 { x + y }
8. ..
범위를 표현할 때 사용합니다.
for i in 1..5 { println!("{}", i); // 1, 2, 3, 4 출력 (5는 포함X) }
..는 시작값 이상, 끝값 미만의 범위를 의미하며, 끝값을 포함할 때는 ..=으로 사용합니다.
9. &
참조(Reference)를 의미합니다.
let x = 3; let y = &x;
y는 x의 참조를 가집니다 (메모리 주소 공유).
10. *
역참조(Dereference)를 의미합니다.
let x = 5; let y = &x; println!("{}", *y); // y가 참조하는 실제 값(x) 출력
*y는 y가 가리키는 값을 가져옵니다.
11. @
의미: 패턴 매칭에서 값 바인딩
let v = Some(10); if let id @ Some(x) = v { println!("id: {:?}", id); }
id @ Some(x)는 Some(10) 전체를 id에 바인딩합니다.
Ⅱ. 연산자
1. 산술 연산자
연산자
설명
예시
결과 설명
+
덧셈
let a = 10 + 5;
a는 15
–
뺄셈
let b = 10 – 5;
b는 5
*
곱셈
let c = 10 * 5;
c는 50
/
나눗셈
let d = 10 / 2
d는 5
%
나머지
let e = 10 % 3
e는 1
2. 비교(관계) 연산자
연산자
설명
예시
결과
==
같다
a == b
true 또는 false
!=
같지 않다
a != b
true 또는 false
>
크다
a > b
true 또는 false
<
작다
a < b
true 또는 false
>=
크거나 같다
a >= b
true 또는 false
<=
작거나 같다
a <= b
true 또는 false
3. 논리 연산자
연산자
설명
예시
결과
&&
논리 AND
(a > 1 ) && (b < 5)
둘 다 true면 true
<code>||</code>
논리 OR
`(a == 1)
!
논리 NOT
!is_valid
true->false, false->true
4. 비트 연산자
연산자
설명
예시
결과
&
비트 AND
a & b
각 비트 AND
<code>|</code>
비트 OR
`a
b`
^
비트 XOR
a ^ b
각 비트 XOR
!
비트 NOT
!a
각 비트 반전
<<
왼쪽 시프트
a << 2
비트를 왼쪽 이동
>>
오른쪽 시프트
a >> 1
비트를 오른쪽 이동
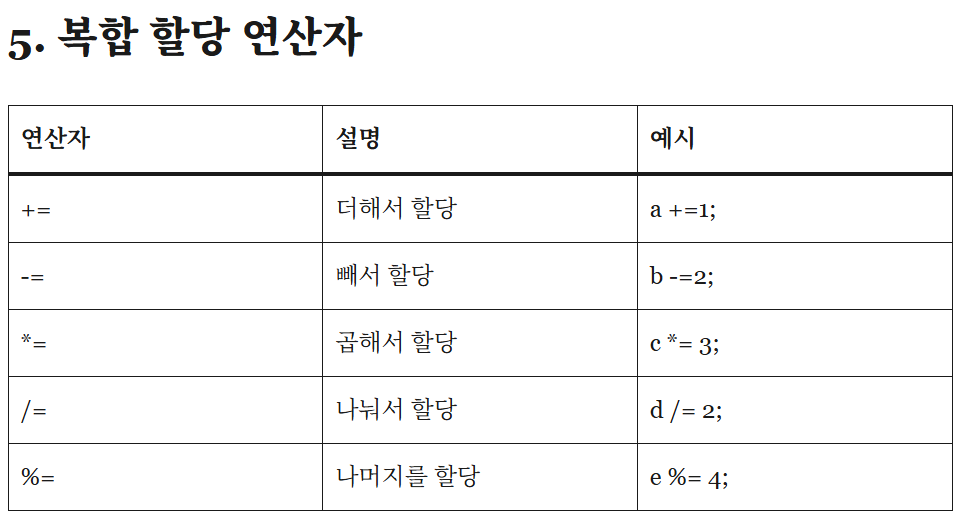
5. 복합 할당 연산자
연산자
설명
예시
+=
더해서 할당
a +=1;
-=
빼서 할당
b -=2;
*=
곱해서 할당
c *= 3;
/=
나눠서 할당
d /= 2;
%=
나머지를 할당
e %= 4;
※ Rust는 ++와 –(증가/감소 연산자)를 지원하지 않습니다.
6. 기타 연산자
가. as: 타입 변환
let x: f32 = 10 as f32;
나. 단항 부정 연산자
-a : a의 음수 !a : a의 반전
Ⅲ. 패턴 매칭 관련 연산자 및 문법
match는 여러 패턴에 따라 코드를 분기할 수 있는 핵심 문법으로, C 계열의 switch보다 다양하고 강력한 매칭을 제공합니다.
let value = Some(7); match value { Some(x) if x > 5 => println!("greater than five: {}", x), Some(x) => println!("got: {}", x), None => println!("no value"), }
1. | (or 패턴 연산자)
여러 패턴을 한 번에 처리할 수 있습니다.
let x = 1; match x { 1 | 2 => println!("one or two"), 3 => println!("three"), _ => println!("other"), }
이 예시에서 1 | 2는 x가 1 또는 2일 때 모두 해당 arm을 실행합니다.
2. _ (와일드카드/전부수용 패턴)
모든 값을 의미하며, 사용하지 않을 값을 무시할 때 씁니다.
match some_value { 1 => println!("one"), _ => println!("other"), }
3. @ (패턴 바인딩 연산자)
패턴과 동시에 값을 바인딩할 때 사용합니다.
let v = Some(42); match v { id @ Some(n) if n > 40 => println!("big! {:?}", id), _ => println!("other"), }
id @ Some(n)은 Some(42) 전체를 id에 바인딩하면서 n 값도 패턴 매칭합니다.
4. if let
특정 패턴만 처리하고 나머지는 무시하고 싶을 때 간결하게 쓸 수 있는 문법입니다.
if let Some(x) = option { println!("have value: {}", x); }
5. while let
while let은Rust에서 반복문과 패턴 매칭을 결합해, 어떤 값이 특정 패턴에 계속 일치하는 동안만 루프를 실행하는 구문입니다. 보통 Option, Result, Iterator 등에서 값을 꺼내거나 처리할 때 매우 자주 사용됩니다.
가. Stack처럼 값 꺼내기
let mut stack = vec![1, 2, 3];
while let Some(top) = stack.pop() { println!("스택에서 꺼냄: {}", top); }
벡터에서 값을 꺼내는 동작이지만, 동시에 벡터를 스택(LIFO)처럼 쓰는 대표적인 패턴이라 “스택처럼 값 꺼내기”라고 표현한 것입니다.
stack.pop()이 벡터의 마지막 요소를 꺼내서(Some) 반환합니다. 벡터가 비어 있다면 None을 반환합니다. Vec은 동적 배열이지만, pop은 이를 스택처럼 사용하게 해 줍니다.
값이 없을 때 None이 반환되고 루프가 끝납니다.
나. Option을 이용한 카운팅
let mut optional = Some(0);
while let Some(i) = optional { if i > 9 { println!("9보다 커서 종료!"); optional = None; } else { println!("현재 값: {}", i); optional = Some(i + 1); } }
optional이 Some(i)에 매칭되는 동안 루프 실행.
다. Result 타입, Iterator 등에도 활용
let mut results = vec![Ok(1), Err("Error"), Ok(2)];
while let Some(res) = results.pop() { match res { Ok(v) => println!("ok: {}", v), Err(e) => println!("err: {}", e), } }
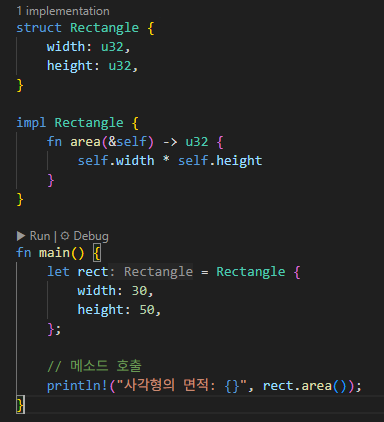
Function은 특정 구조체나 인스턴스와 관계없이 독립적으로 정의되는데, Method는 구조체(또는 enum) 인스턴스의 상태를 읽거나 변경하는 동작을 구현하며, Assosiated Functions는 특정 타입과 연결되어 있지만 해당 타입의 인스턴스와는 독립적인 함수를 의미합니다.
1. 함수와 메소드의 차이점
가. 함수 (Function)
특정 구조체나 인스턴스와 관계없이 독립적으로 정의됩니다.
fn 키워드를 사용해 선언하며, 어디서든 호출할 수 있습니다.
호출 시 add(3, 5)처럼 함수 이름만 사용합니다.
fn add(a: i32, b: i32) -> i32 {
a + b
}
나. 메소드 (Method)
구조체(struct), 열거형(enum) 등 특정 타입의 impl 블록 안에서 정의됩니다.
첫 번째 파라미터로 반드시 self, &self, &mut self 중 하나를 받습니다.
인스턴스를 통해서만 호출할 수 있으며, rect.area()처럼 점(.) 연산자를 사용합니다.
Rust의 slice(슬라이스)는 배열, 벡터, 문자열 등 메모리상에 연속적으로 저장된 데이터의 일부 구간을 참조하는 타입이고, 컬렉션 참조는 컬렉션(배열 포함) 전체에 대한 참조입니다. 그러나, 모두 소유권을 갖지 않고 데이터를 참조하는 것은 같지만, 그 목적과 내부 구조, 사용 방식에 중요한 차이가 있습니다.
1. 슬라이스(Slice)
가.기본 개념
슬라이스는 배열, 벡터, 문자열 등 메모리상에 연속적으로 저장된 데이터의 일부 구간을 참조하는 타입으로, &[T] 또는 &str(문자열 슬라이스)와 같이 참조 형태로 표현된다.
슬라이스는 원본 데이터의 소유권을 이동시키지 않으며, 원본 데이터가 유효할 때만 사용할 수 있다.
슬라이스는 연속된 메모리 블록의 시작 주소와 길이 정보를 함께 저장하는 fat pointer(두 개의 값: 포인터 + 길이)이다.
슬라이스는 항상 연속적인 데이터만 참조할 수 있습니다.
나.문법과 사용법
슬라이스는 [start..end] 범위 문법을 사용합니다.
start는 포함, end는 포함하지 않습니다(즉, 반 열린 구간). let a = [1, 2, 3, 4, 5]; let slice = &a[1..4]; // [2, 3, 4]
start나 end를 생략하면 처음이나 끝을 의미합니다. &a[..3] → 처음부터 3번째 전까지 &a[2..] → 2번째부터 끝까지(끝 포함) &a[..] → 전체
다. 문자열 슬라이스
문자열 슬라이스는 String이나 문자열 리터럴의 일부를 참조하며 타입은 &str 입니다.
문자열 일부 참조 let s = String::from(“hello world”); let hello = &s[0..5]; // “hello” let world = &s[6..11]; // “world”
문자열 리터럴 let s = “hello, world”; // &’static str let part: &str = &s[0..5]; // “hello” 부분만 참조 “hello” 자체도 &str 타입의 슬라이스이므로, 문자열 리터럴의 일부도 참조할 수 있습니다.
라. 특징과 주의점
슬라이스는 참조이므로, 원본 데이터가 유효해야 한다. 원본 데이터가 변경(예: String의 clear 등)되면 기존 슬라이스는 무효화되어 컴파일 에러가 발생합다.
슬라이스는 소유권과 라이프타임 개념을 이해하는 데 중요한 역할을 합니다. -> 아래 ‘3. 슬라이스와 라이프타임’에서 설명
슬라이스는 함수의 파라미터로 자주 사용됩니다.
fn main() {
let s = "hello, world";
println!("First two elements: {:?}", first_two(s));
}
fn first_two(slice: &str) -> &str {
if slice.len() < 2 {
panic!("Slice must have at least two elements");
}
&slice[0..2]
}
위 코드에서 s는 문자열 리터럴인 문자열 슬라이스이므로 함수로 넘길 때는 &를 안붙여도 되지만(붙여도 됨), 함수에서 받을 때는 타입을 &str으로 지정하고, 반환도 &slice[0..2]이므로&str 타입으로 지정해야 합니다.
실행 결과는 First two elements: “he”입니다.
2. 컬렉션 참조
가. 개념
컬렉션 참조는 컬렉션 전체에 대한 참조입니다. 예를 들어, &Vec, &String, &[T; N] 등입니다. 여기서 &[T; N]은 배열 전체에 대한 참조입니다. 엄격하게 말하면 배열은 컬렉션은 아니지만 “배열 전체를 참조한다”는 측면에서 컬렉션 참조에 포함해서 설명합니다.
이 참조는 해당 컬렉션 타입의 모든 메서드와 속성을 사용할 수 있게 해줍니다.
컬렉션 참조는 그 자체가 소유한 데이터 전체를 가리키며, 슬라이스처럼 부분만을 가리키지는 않습니다.
예시: let v = vec![1, 2, 3]; let r = &v; // Vec 전체에 대한 참조
벡터 컬렉션 참조의 간단한 예시는 다음과 같습니다.
fn main() { let v = vec![100, 32, 57]; // Vec<i32> 생성 // 벡터에 대한 불변 참조를 사용하여 각 요소 출력 for i in &v { println!("{}", i); } }
여기서 &v는 Vec 타입의 벡터에 대한 불변 참조(&Vec)입니다.
for i in &v 구문은 벡터의 각 요소에 대한 참조(&i32)를 순회하며 안전하게 접근합니다.
fn main() { let data = [10, 20, 30]; print_array(&data); // &[i32; 3] 타입의 참조 전달 }
위 예제에서 print_array 함수는 크기가 3인 i32 배열에 대한 참조(&[i32; 3])를 인자로 받습니다.
&data는 [i32; 3] 타입 배열 전체에 대한 참조입니다.
다. 슬라이스와 주요 차이점 비교
구분
슬라이스 (&[T], &str)
컬렉션 참조 (&Vec<T>, &String)
대상
컬렉션의 일부(연속 구간)
컬렉션 전체
내부 구조
포인터 + 길이 (fat pointer)
포인터 (컬렉션 구조체 전체)
메서드 사용
슬라이스 관련 메서드만 사용 가능
컬렉션의 모든 메서드 사용 가능(벡터의 len(), push() 등
용도
부분 참조, 함수 인자 등
전체 참조, 컬렉션의 메서드 활용
동적 크기
길이가 런타임에 결정됨
컬렉션 타입에 따라 다름
예시
&arr[1..3], &vec[..], &s[2..]
&vec, &arr, &String
&[T; N]은 배열 전체를 참조하고, &[T]는 슬라이스로, 배열의 일부 구간(혹은 전체)을 참조할 수 있습니다. 예를 들어, &arr[1..3]은 &[T] 타입(슬라이스)이지만, &arr은 &[T; N] 타입(컬렉션 참조)입니다. 이처럼 &[T; N]은 정확히 N개 원소를 가진 배열 전체에 대한 참조입니다.
또한 &str과 &String은 문자열 슬라이스와 문자열 참조로 다르지만, &String이 &str으로 자동 변환이 가능하기 때문에 함수 인자로는 &str이 더 범용적이고 권장됩니다.
3. 슬라이스와 라이프타임
가. 개념
Rust에서 라이프타임(lifetime)은 참조가 유효한 기간을 명확하게 지정하는 개념으로, 참조의 유효성에 직접적인 영향을 미칩니다. 라이프타임이 중요한 이유와 그 영향은 다음과같습니다.
댕글링 참조 방지 라이프타임의 가장 큰 목적은 댕글링 참조(dangling reference)를 방지하는 것입니다. 댕글링 참조란, 이미 스코프를 벗어나 소멸된 데이터를 참조하는 상황을 의미합니다. Rust는 각 참조자의 라이프타임을 추적하여, 참조가 원본 데이터보다 오래 살아남을 수 없도록 컴파일 타임에 강제합니다.
안전한 메모리 접근 보장 라이프타임을 통해 참조자가 항상 유효한 메모리만 가리키도록 보장합니다. 예를 들어, 아래와 같은 코드는 컴파일되지 않습니다.
let r; // r의 라이프타임 시작 { let x = 5; // x의 라이프타임 r = &x; // r이 x를 참조 } // x의 라이프타임 종료, r은 더 이상 유효하지 않음 println!(“{}”, r); // 컴파일 에러! Rust는 위 코드에서 r이 x보다 오래 살아남으려 하므로 컴파일 에러를 발생시킵니다.
함수와 구조체에서의 명확한 라이프타임 관계 여러 참조가 얽히는 함수나 구조체에서는, 각각의 참조가 얼마나 오래 유효해야 하는지 명확히 지정해야 합니다. 라이프타임 파라미터를 명시함으로써, 함수가 반환하는 참조가 입력 참조자 중 어느 것과 연관되어 있는지 컴파일러가 알 수 있습니다.
암묵적 추론과 명시적 지정 대부분의 경우 Rust는 라이프타임을 자동으로 추론하지만, 여러 참조가 얽히거나 복잡한 관계가 있을 때는 명시적으로 라이프타임을 지정해야 합니다. 이를 통해 참조 유효성에 대한 컴파일러의 보장이 더욱 강력해집니다.
나. 예제 1
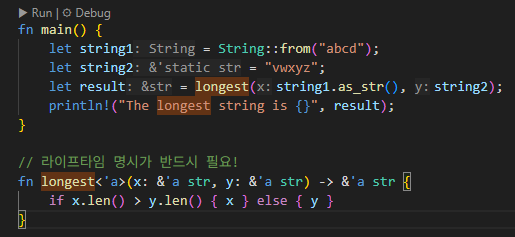
Rust에서 슬라이스의 라이프타임이 중요한 이유를 보여주는 대표적인 예제는, 두 개의 문자열 슬라이스 중 더 긴 쪽을 반환하는 함수입니다. 이 예제를 통해 슬라이스의 라이프타임을 명확히 지정하지 않으면 컴파일 에러가 발생하고, 올바르게 지정하면 안전하게 참조를 반환할 수 있음을 알 수 있습니다.
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {}", result); }
// 라이프타임 명시가 반드시 필요! fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
이 함수 시그니처에서 ‘a라는 라이프타임 파라미터를 명시했습니다.
이 뜻은, x와 y 모두 최소한 ‘a만큼 살아 있어야 하며, 반환되는 슬라이스도 ‘a만큼 살아 있어야 한다는 의미입니다.
실제로 함수가 호출될 때, Rust는 x와 y의 라이프타임 중 더 짧은 쪽에 맞춰 반환값의 라이프타임을 제한합니다. 따라서, ‘a와 ‘b를 사용해서 fn longest<‘a, ‘b>(x: &’a str, y: &’b str) -> &’a str 라고 하면 x가 반환될 수도 있고 y가 반환될 수도 있기 때문에 에러가 발생합니다.
또한 라이프타임을 명시하지 않아도, Rust는 반환되는 참조가 입력 참조자 중 어느 쪽과 연관되어 있는지 알 수 없어 컴파일 오류가 발생합니다. 따라서, 라이프타임을 ‘a로 통일한 것입니다.
이처럼, 슬라이스의 라이프타임을 명확히 지정하지 않으면 댕글링 참조가 생길 수 있고, Rust는 이를 컴파일 타임에 방지합니다. 따라서 라이프타임 명시는 슬라이스가 안전하게 사용될 수 있는 핵심적인 장치입니다.
위 코드에서 as_str()은 String 타입을 &str 타입으로 변환하는 메소드입니다.
다. 예제2
fn main() { let result; { let string1 = String::from("abc"); let string2 = String::from("xyz"); result = longest(string1.as_str(), string2.as_str()); // string1, string2는 여기서 소멸 } println!("The longest string is {}", result); // 컴파일 에러! }
위 코드는 result가 내부 스코프의 데이터인 string1 또는 string2의 슬라이스를 참조하게 되므로, 컴파일 에러를 발생시켜 댕글링 참조를 차단합니다.