Rust에서 array와 vector는 모두 여러 개의 값을 순차적으로 저장하는 자료구조입니다. 하지만 두 타입은 메모리 관리, 크기, 사용 목적 등에서 중요한 차이점이 있습니다. 이 글에서는 각 자료구조의 특징, 사용법, 예제, 그리고 언제 어떤 것을 선택해야 하는지에 대해 자세히 알아보겠습니다.
1. Array(배열)
1.1. 기본 개념
- 고정 크기: 배열은 선언 시 크기가 고정되며, 이후 변경할 수 없습니다.
- 동일 타입: 배열의 모든 원소는 같은 타입이어야 합니다.
- 스택 메모리: 배열은 스택에 저장되어 빠른 접근이 가능합니다.
1.2. 배열 선언과 사용 예제
fn main() {
let arr: [i32; 5] = [1, 2, 3, 4, 5];
println!("첫 번째 원소: {}", arr[0]);
println!("배열의 길이: {}", arr.len());
// 배열 반복
for elem in arr.iter() {
println!("{}", elem);
}
}
- [i32; 5]는 5개의 i32 타입 값을 가지는 배열을 의미합니다.
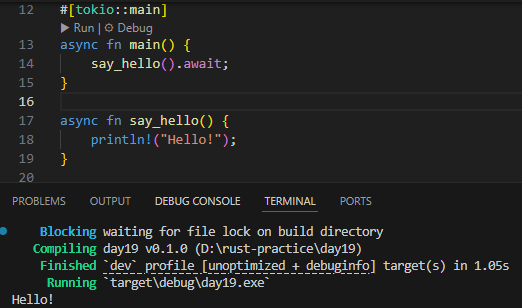
- 배열의 크기는 타입의 일부이므로, arr은 항상 5개의 요소만 가질 수 있습니다.
- arr.iter()로 반복(소유권 이전이 안되며, arr.iter()를 &arr로 바꿔도 됨)해서 요소를 elem에 할당한 후 그 값을 화면에 표시합니다.
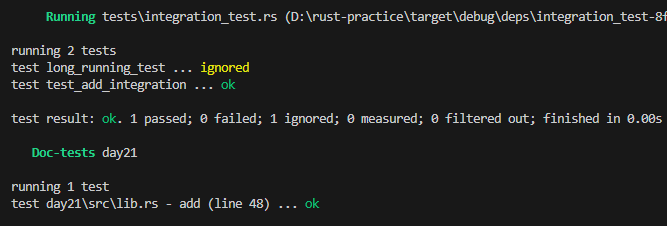
전체적인 출력 결과는 아래와 같습니다.

1.3. 배열의 주요 특징
- 정적 크기: 크기가 컴파일 타임에 결정됩니다.
- 빠른 접근: 인덱스를 통한 접근이 가능합니다.
- 복사: 크기가 작을 경우, 배열 전체가 복사될 수 있습니다.
1.4. 배열의 한계
- 크기를 동적으로 변경할 수 없습니다.
- 대용량 데이터에는 적합하지 않을 수 있습니다.
2. Vector(벡터)
2.1. 기본 개념
- 동적 크기: 벡터는 런타임에 크기를 자유롭게 변경할 수 있습니다.
- 동일 타입: 모든 원소는 동일한 타입이어야 합니다.
- 힙 메모리: 벡터는 힙에 저장되어 대용량 데이터 처리에 적합합니다.
2.2. 벡터 선언과 사용 예제
fn main() {
let mut vec: Vec<i32> = Vec::new();
vec.push(10);
vec.push(20);
vec.push(30);
println!("두 번째 원소: {}", vec[1]);
println!("벡터의 길이: {}", vec.len());
// 벡터 반복
for elem in &vec {
println!("{}", elem);
}
// 벡터에서 값 제거
vec.pop();
println!("마지막 원소 제거 후: {:?}", vec);
}
- Vec::new()로 빈 벡터를 생성하면 type을 추론할 수 없으므로 Vec 다음에 <i32>가 반드시 있어야 합니다.
- push로 값을 추가하고, pop으로 마지막 값을 제거합니다.
- 벡터는 mut로 선언해야 원소 추가/삭제가 가능합니다.
- vec 요소를 소유권 이전없이 참조로 하나씩 꺼내서 elem에 넣은 다음 출력합니다. 배열과 마찬가지로 &vec을 vec.iter()로 바꿔도 됩니다.
전체적인 출력은 아래와 같습니다.
두 번째 원소: 20(인덱스가 0부터 시작하기 때문에 1이 두번째 원소가 됩니다)
벡터의 길이: 3
10
20
30
마지막 원소 제거 후: [10, 20]
2.3. 벡터의 주요 특징
- 가변 크기: 필요에 따라 자동으로 크기가 늘어남.
- 유연성: 다양한 상황에 맞게 사용할 수 있음.
- 힙 저장: 대용량 데이터에도 적합.
2.4. 벡터의 한계
- 배열에 비해 약간의 오버헤드가 발생할 수 있음.
- 힙에 저장되므로 스택보다 접근 속도가 느릴 수 있음.
3. Array vs Vector 비교
| 특징 | Array(배열) | Vector(벡터) |
|---|---|---|
| 크기 | 고정 | 동적 |
| 선언 위치 | 스택 | 힙 |
| 선언 방식 | [T; N] | Vec<T> |
| 값 추가/제거 | 불가 | 가능 (push, pop 등) |
| 반복 | .iter() | .iter() |
| 사용 예시 | 소규모, 고정 데이터 | 대규모, 가변 데이터 |
4. 실전 예제: 배열과 벡터 변환
4.1. 배열을 벡터로 변환
fn main() {
let arr = [1, 2, 3];
let vec = arr.to_vec();
println!("{:?}", vec); // [1, 2, 3]
}
4.2. 벡터를 배열로 변환
- 벡터의 길이가 고정되어 있고, 크기를 알고 있을 때만 가능합니다.
fn main() {
let vec = vec![4, 5, 6];
let arr: [i32; 3] = vec.try_into().unwrap();
println!("{:?}", arr); // [4, 5, 6]
}
5. 벡터의 다양한 메서드
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
// 값 삽입
v.insert(2, 99); // 2번 인덱스에 99 삽입
// 여러 개의 값 추가
v.extend([6, 7, 8, 9]);
// 값 삭제
v.remove(1); // 1번 인덱스 값 제거
// 슬라이스
let slice = &v[1..3];
println!("{:?}", slice);
// 반복자 메서드
let doubled: Vec<i32> = v.iter().map(|x| x * 2).collect();
println!("{:?}", doubled);
}
- v.insert(2, 99)
=> 2번 인덱스에 99를 추가하니 벡터 v는 [1, 2, 99, 3, 4, 5]가 됩니다. - v.extend([6, 7, 8, 9]);
=> push는 맨 뒤에 값 하나를 추가하는데, extend를 한 번에 여러 개의 값을 추가할 수 있습니다. 따라서, v는 [1, 2, 99, 3, 4, 5, 6, 7, 8, 9]가 됩니다. - v.remove(1);
=> 1번 인덱스인 2를 제거하므로 v는 [1, 99, 3, 4, 5, 6, 7, 8, 9]가 됩니다. - let slice = &v[1..3];
println!(“{:?}”, slice);
=> v 벡터에서 1번 인덱스부터 3미만인 2번 인덱스까지 참조 형식으로 가져오는 slice는 [99, 3]이 됩니다.
Vector는 일반 포맷인 {}로는 출력이 안되므로 디버그 포맷인 {:?}으로 출력해야 합니다.
- let doubled: Vec<i32> = v.iter().map(|x| x * 2).collect();
println!(“{:?}”, doubled);
=> v 벡터의 요소 들에 2를 곱한 후 새로운 벡터로 변환한 후 doubled에 저장합니다. doubled의 타입도 i32타입의 Vector이므로 디버그 포맷으로 출력하면
[2, 198, 6, 8, 10, 12, 14, 16, 18]가 출력됩니다.
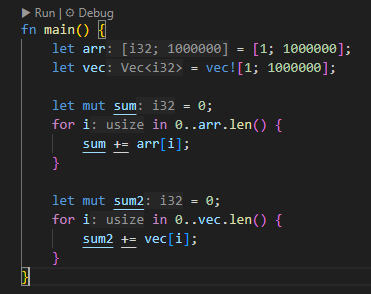
6. 성능 차이의 실제 사례
6.1. 반복문에서의 성능
fn main() {
let arr = [1; 1000000];
let vec = vec![1; 1000000];
let mut sum = 0;
for i in 0..arr.len() {
sum += arr[i];
}
let mut sum2 = 0;
for i in 0..vec.len() {
sum2 += vec[i];
}
}
- 실행 시간: 배열이 벡터보다 약간 더 빠른 경우가 많습니다.
- 이유: 배열은 스택에 연속적으로 저장되어 CPU 캐시 효율이 높고, 컴파일러가 최적화를 더 적극적으로 적용할 수 있습니다.
위와 같이 배열의 개수를 1백만개로 숫자가 1인데도 array의 경우 overflow가 발생하므로 1십만으로 바꾸는데, 시간을 체크하는 부분을 추가하고, 천단위 쉼표를 추가하도록 아래와 같이 수정한 후
[Cargo.toml] -num-format 크레이트를 사용하기 위해 필요
[dependencies]
num-format = "0.4"
[main.rs]
use std::time::Instant;
use num_format::{Locale, ToFormattedString};
fn main() {
let arr = [1; 100_000];
let vec = vec![1; 100_000];
// 배열 합계 시간 측정
let start = Instant::now();
let mut sum = 0;
for i in 0..arr.len() {
sum += arr[i];
}
let duration = start.elapsed();
println!("Array sum: {}, elapsed: {:?}", sum.to_formatted_string(&Locale::ko), duration);
// 벡터 합계 시간 측정
let start = Instant::now();
let mut sum2 = 0;
for i in 0..vec.len() {
sum2 += vec[i];
}
let duration = start.elapsed();
println!("Vector sum: {}, elapsed: {:?}", sum2.to_formatted_string(&Locale::ko), duration);
}
실행하면 결과는 아래와 같습니다.
Array sum: 100,000, elapsed: 806.2µs
Vector sum: 100,000, elapsed: 2.3802ms
1㎳가 1000㎲이므로, Vector가 약 3배정도 오래 걸립니다.
[프로그램 설명]
- Rust의 표준 라이브러리에서 제공하는
std::time::Instant을 사용해 각 합계 연산의 소요 시간을 측정합니다.
- Instant::now()로 현재 시각을 기록하고, 반복문이 끝난 후 elapsed()로 소요 시간을 구합니다.
- for i in 0..arr.len()라고 0부터 배열의 길이전까지 i를 반복하면 sum에 arr[i]를 더하도록 했는데, for i in arr.iter()라고 하고, sum += i;이라고 해도 되는데, iter()를 이용한 것이 훨씬 빠릅니다. 특히 Vector 속도가 많이 빨라졌습니다.
Array sum: 100,000, elapsed: 728.6µs
Vector sum: 100,000, elapsed: 875.7µs
※ 그런데 매번 속도가 다르기 때문에 위 수치가 절대적인 것은 아닙니다. 어느 때는 Vector가 빠른 경우도 있습니다. - sum 또는 sum2 다음에 num_format의 ToFormattedString(&Locale::ko)를 추가해서 숫자에 천단위마다 쉼표를 추가합니다.
6.2. 크기 변경 및 데이터 추가
- 배열은 크기가 고정되어 있어, 데이터 추가/삭제가 불가능합니다.
- 벡터는 push, pop, extend 등으로 동적으로 크기를 조절할 수 있지만, 이 과정에서 메모리 재할당이 발생할 수 있습니다. 대량의 데이터를 추가할 때는 재할당 오버헤드가 성능 저하 요인이 됩니다.
6.3. 벤치마크 및 실제 사용 조언
- 고정 크기, 빠른 반복/접근이 필요하다면 배열이 유리합니다.
- 크기가 가변적이거나, 데이터 추가/삭제가 빈번하다면 벡터가 적합합니다.
- 대용량 데이터 처리에서 벡터는 힙 할당 및 재할당 비용이 있으므로, 성능이 민감한 경우 벡터의 용량을 미리 예약(with_capacity)하는 것이 좋습니다.
※with_capacity란?
- Vec::with_capacity는 Rust의 벡터(Vec)를 생성할 때 초기 용량(capacity) 을 미리 지정하는 메서드입니다.
- with_capacity(n)은 최소 n개의 요소를 저장할 수 있는 공간을 미리 할당한 빈 벡터를 생성합니다.
- 이렇게 하면, 벡터에 요소를 추가할 때마다 메모리를 재할당하는 비용을 줄일 수 있어 성능이 향상됩니다.
- 사용 예시
fn main() {
let mut vec = Vec::with_capacity(10);
assert_eq!(vec.len(), 0);
assert!(vec.capacity() >= 10);
for i in 0..10 {
vec.push(i);
}
assert_eq!(vec.len(), 10);
assert!(vec.capacity() >= 10);
// 11번째 push 시 재할당 발생 가능
vec.push(11);
assert_eq!(vec.len(), 11);
}
- 위 예제에서 vec은 처음부터 10개 이상의 요소를 저장할 수 있도록 메모리를 할당받아, 10개까지는 재할당 없이 push가가능합니다.
- 11번째 요소를 추가하면 내부 용량을 초과하므로 재할당이 발생할 수 있습니다.
7. 요약 표
| 구분 | 배열 (Array) | 벡터 (Vector) |
|---|---|---|
| 저장 위치 | 스택 | 힙 |
| 크기 | 고정 | 동적 |
| 접근 속도 | 매우 빠름 | 빠르나 배열보다 느림 |
| 데이터 추가/삭제 | 불가 | 가능 |
| 성능 | 반복/접근에서 우위 | 대용량·가변성에 우위 |



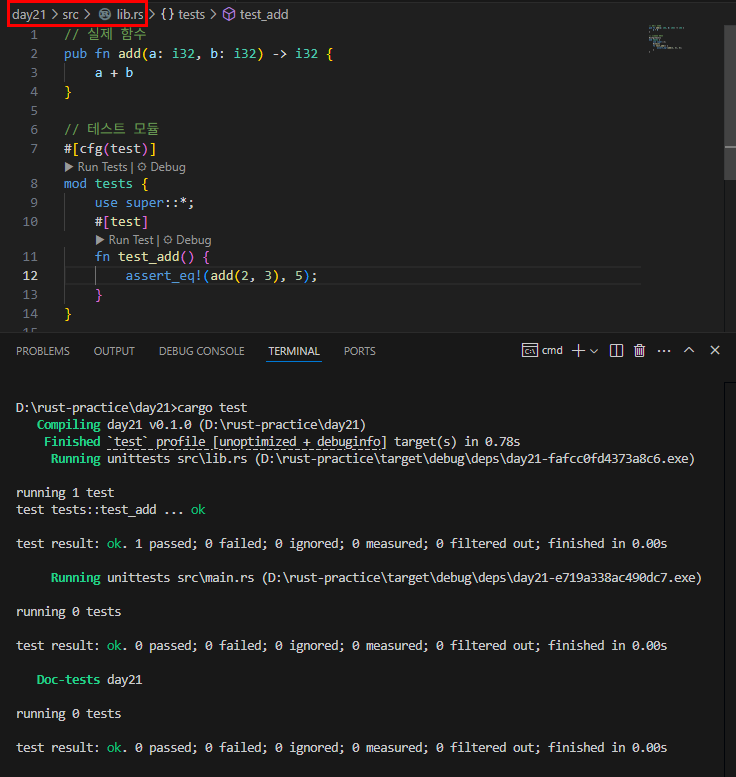
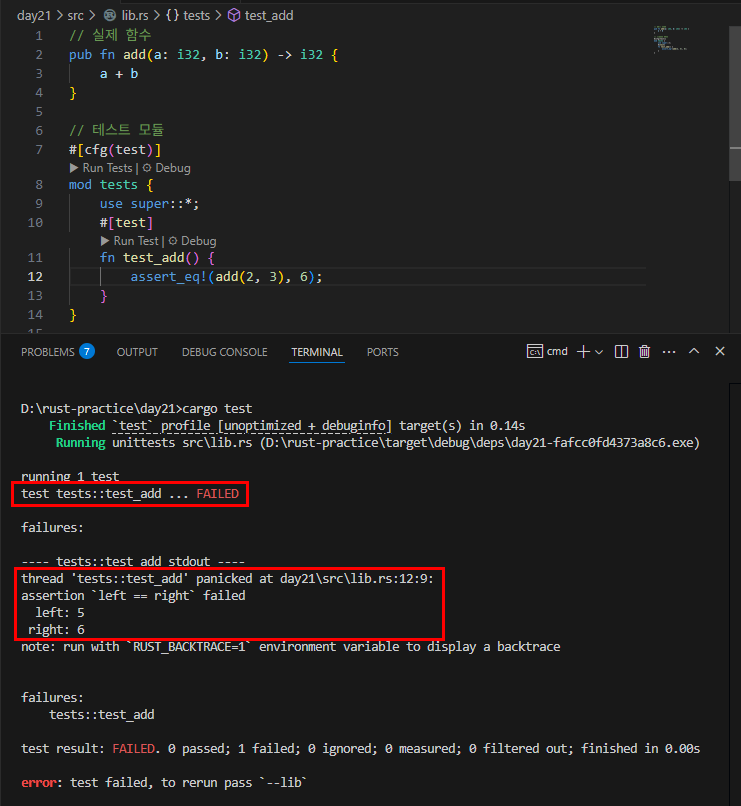

![테스트 함수에서 panic이 발생하면 :
#[should_panic]: panic이 발생해야 ok](https://overmt.com/wp-content/uploads/2025/07/test6.webp)
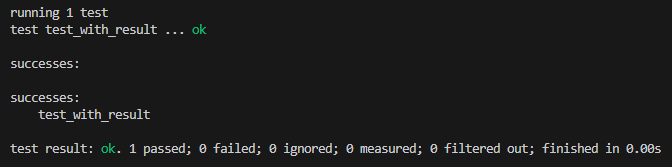
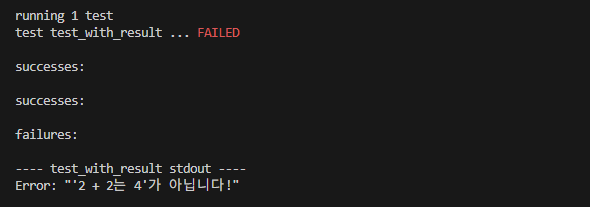
![#[ignore] - 테스트시 제외](https://overmt.com/wp-content/uploads/2025/07/image-8.png)
![#[ignore]가 붙은 테스트만 실행](https://overmt.com/wp-content/uploads/2025/07/image-9.png)