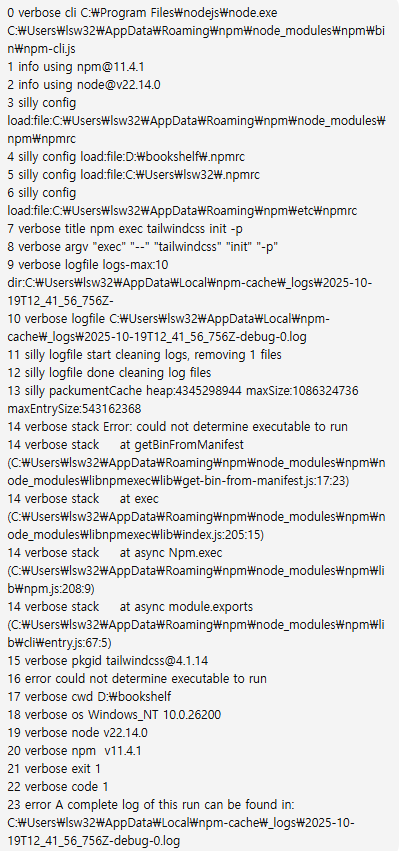
npm으로 tailwincss 설치시 “npm error could not determine executable to run”가 발생한다면 tailwindcss 버전이 맞지 않아서 그런 것이므로 낮은 버전을 설치하던가, package.json 파일을 수정한 다음 설치해야 합니다.
아래는 구체적인 에러 메시지 내용입니다.
1. 원인
핵심 오류는 이 부분이에요 👇
Error: could not determine executable to run
verbose pkgid tailwindcss@4.1.14
npm 11 + tailwindcss 최신 버전(4.x) 조합에서 발생하는 공식적으로 보고된 버그입니다. 현재 tailwindcss@4.x는 정식 릴리스가 아니고, npx로 실행 시 **실행 파일(bin)**을 제대로 인식하지 못합니다.
&str는 string literal과 빌림 문자열 두 가지가 있습니다. string literal은 String이 아니고, 큰 따옴표안에 들어가 있는 문자열이고, 빌림 문자열은 문자열을 빌리는 것입니다.
string literal은 static 수명이 있고, 빌림 문자열은 필요한 경우에 static이 아닌 수명을 지정해줘야 합니다.
1. 예시
가. string literal 예시
fn main() {
let my_str = "I am a string";
println!("{}", my_str);
}
my_str 다음의 숨겨진 타입을 보면 &’static str로 되어 있습니다.
println!(“{}”, my_str);을 println!(“{}”, &my_str);로 my_str 앞에 &를 붙여도 동작합니다.
나. &str 예시
fn print_str(my_str: &str) {
println!("{my_str}");
}
fn main() {
let my_str = "I am a string".to_string();
print_str(&my_str);
}
my_str은 .to_string() 함수를 적용해서 string literal을 String 타입으로 변환했고, 이것을 빌리기 위해 my_str앞에 &를 붙여서 print_str의 인수로 전달했습니다.
2. 문자열 리터럴의 lifetime
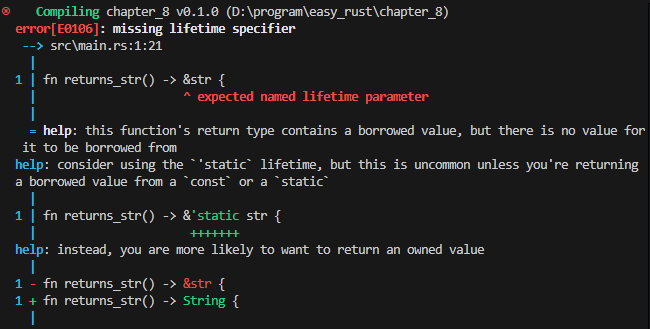
fn returns_str() -> &str {
"I am a str"
}
fn main() {
let my_str = returns_str();
println!("{my_str}");
}
위 코드는 returns_str 함수를 이용해 문자열을 리턴 받은 후 그 문자열을 화면에 출력하려고 하는 것인데,
리턴 타입에서 명명된 라이프타임 파라미터가 기대된다는 에러 메시지가 나오면서 중간에 녹색으로 & 다음에 ‘static을 붙이는 것을 고려하라고 합니다.
반환 값이 “I am a str”, 다시 말해 문자열 리터럴이므로 &’static을 붙여야 합니다.
수정된 코드는 아래와 같습니다.
fn returns_str() -> &'static str {
"I am a str"
}
fn main() {
let my_str = returns_str();
println!("{my_str}");
}
코드를 수정하고 실행하니 ‘I am a str’가 잘 출력됩니다.
위에 &str을 String으로 바꿔보라고 하는 제안도 있었는데, 이것을 적용하면 아래와 같이 됩니다.
fn returns_str() -> String {
"I am a str".to_string()
}
fn main() {
let my_str = returns_str();
println!("{my_str}");
}
String 타입으로 바꾸면 수명 문제도 발생하지 않고, 출력값도 같습니다.
3. &str의 lifetime 1
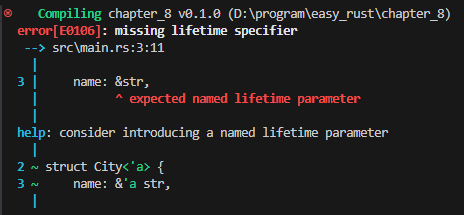
#[derive(Debug)]
struct City {
name: &str,
date_founded: u32,
}
fn main() {
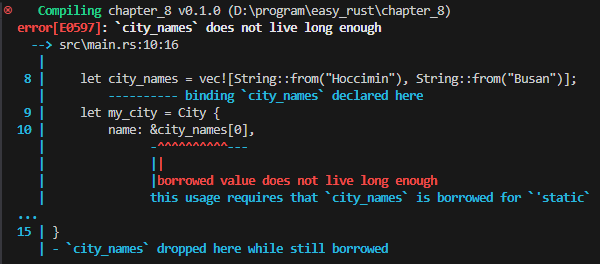
let city_names = vec![String::from("Hoccimin"), String::from("Busan")];
let my_city = City {
name: &city_names[0],
date_founded: 1952,
};
println!("{my_city:?}");
}
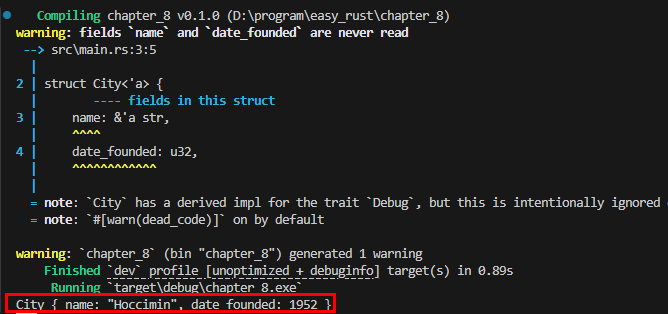
위 코드는 City 구조체를 만든 후 my_city라는 인스턴스를 만드는데, name으로 city_names라는 Vector에서 첫번째 것을 빌림으로 가져와서 대입하고, date_founded는 직접 1952를 입력한 다음 화면에 출력하는 것입니다.
그런데, 실행하면
&str에 명명된 lifetime parameter가 기대된다고 하면서
struct City 다음에 <‘a>를 붙이고, name 필드의 & 다음에도 ‘a를 붙이라고 합니다. 이렇게 하면 “name이 City 만큼 오래 살아야” 하므로 문제가 해결됩니다.
여기서 a는 라이프 타임 파라미터를 지칭하는 것으로 다른 문자를 사용해도 됩니다.
아래와 같이 수정하고 실행하면
#[derive(Debug)]
struct City<'a> {
name: &'a str,
date_founded: u32,
}
fn main() {
let city_names = vec![String::from("Hoccimin"), String::from("Busan")];
let my_city = City {
name: &city_names[0],
date_founded: 1952,
};
println!("{my_city:?}");
}
잘 출력됩니다.
4. &str의 lifetime 2
그러나, &city_names[0]이 문자열 리터럴이 아니고 빌림 문자열이기 때문에 City 필드를 name: &’static str로 수정하면
#[derive(Debug)]
struct City {
name: &'static str,
date_founded: u32,
}
fn main() {
let city_names = vec![String::from("Hoccimin"), String::from("Busan")];
let my_city = City {
name: &city_names[0],
date_founded: 1952,
};
println!("{my_city:?}");
}
아래와 같은 에러가 발생합니다.
“&city_names[0]이라는 빌린 값이 충분히 오래 살지 못한다”고 하고, 그 아래에서는 “이 사용법은 city_names가 ‘static을 위해 빌리는 것이 요구된다”고 합니다. 왜냐하면 City 구조체 정의 시 name 타입 지정시’static 을 사용했기 때문입니다.
따라서, 3번에서와 같이 ‘a를 사용해야 합니다.
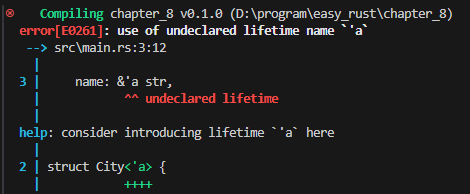
그런데 City 오른쪽에 <‘a>를 추가하지 않고, name 오른쪽에 만 ‘a를 추가하면
struct City { name: &'a str, date_founded: u32, }
선언되지 않은 라이프타임 에러가 발생합니다. 따라서, City 오른쪽에 <‘a>를 추가해서 lifetime을 선언해야 합니다.
아래 코드의 핵심은 Iterator 트레이트의 연관 타입(associated type) 과 트레이트 구현에 의한 타입 유추입니다. Item이 직접적으로 코드 안에서 보이지 않지만, 트레이트 시스템이 자동으로 Iterator trait의 type Item과 연결해 주고 있습니다.
1. 예제 코드
struct GivesOne;
impl Iterator for GivesOne {
type Item = i32;
fn next(&mut self) -> Option<i32> {
Some(1)
}
}
fn main() {
let five_ones = GivesOne.into_iter().take(5).collect::<Vec<i32>>();
println!("{five_ones:?}");
}
2. 구조체 정의
struct GivesOne;
GivesOne은 단순한 빈 구조체입니다.
3.Iterator 트레이트 구현
impl Iterator for GivesOne {
type Item = i32;
fn next(&mut self) -> Option<i32> {
Some(1)
}
}
여기서 중요한 부분이 바로 type Item = i32; 입니다. Iterator 트레이트는 아래와 같이 정의되어 있습니다 (표준 라이브러리 축약본).
::은 “어디에 속한 항목인지” 또는 “어떤 타입인지”를 명시할 때 쓰이며, enum일 수도, 모듈일 수도, 제네릭 타입 지정(Turbofish)일 수도 있으며, 연관 함수, 상수 또는 연관 상수에 접근할 때도 사용되고, 트레이트 경로를 통한 메소드 호출 시에도 사용됩니다.
1. Rust에서 ::의 용도 정리표
구분
예시
설명
관련 키워드
모듈/경로 구분자
std::fs::File
모듈(std) → 하위 모듈(fs) → 항목(File)로 내려가는 경로 지정
모듈(module), 네임스페이스(namespace)
enum variant 접근
Option::Some(5)
Optionenum 안의 Somevariant에 접근
enum
연관 함수(associated function) 접근
String::from(“hi”)
타입(String)의 연관 함수(from) 호출
struct, enum, trait
상수 또는 연관 상수 접근
std::f64::consts::PI
f64타입의 연관 상수 PI에 접근
상수(const)
Turbofish (제네릭 타입 명시)
“42”.parse::<i32>()
제네릭 함수의 타입 매개변수를 명시적으로 지정
제네릭(Generic)
제네릭 타입 생성 시 타입 지정
Vec::<i32>::new()
제네릭 타입(Vec<T>)의 매개변수를 명시적으로 지정
제네릭 타입
트레이트 경로를 통한 메서드 호출
<T as SomeTrait>::method()
특정 트레이트에 정의된 메서드를 명시적으로 호출
트레이트(impl 충돌 해결용)
2. 예시 모음
mod math {
pub const PI: f64 = 3.14;
}
#[derive(Debug)]
#[allow(dead_code)]
enum Color {
Red,
Blue,
}
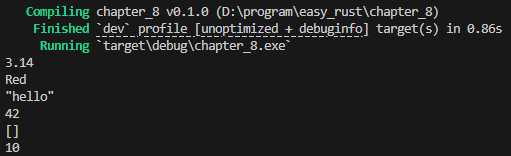
fn main() {
// 1️⃣ 모듈 경로
println!("{}", math::PI); // -> 3.14
// 2️⃣ enum variant 접근
let c = Color::Red;
println!("{c:?}");
// 3️⃣ 연관 함수
let s = String::from("hello");
println!("{s:?}");
// 4️⃣ Turbofish
let n = "42".parse::<i32>().unwrap();
println!("{n:?}");
// 5️⃣ 제네릭 타입 지정
let v = Vec::<i32>::new();
println!("{v:?}");
// 6️⃣ 트레이트 메서드 명시 호출
use std::string::ToString;
let x = 10;
let s = <i32 as ToString>::to_string(&x);
println!("{}", s); // "10"
}
BinaryHeap은 가장 큰 값을 맨 앞에 위치시키고, 나머지 값들은 임의의 순서대로 저정하지만, pop()을 사용하면 내림차순으로 정렬한 것처럼 보이게 할 수 있습니다.
1. 코드
use std::collections::BinaryHeap;
fn main() {
let mut jobs = BinaryHeap::new();
jobs.push((100, "Write back to email from the CEO"));
jobs.push((80, "Finish the report today"));
jobs.push((5, "Watch Some YouTube"));
jobs.push((70, "Tell your team members thanks for always working hand"));
jobs.push((30, "Plan who to hire next for the team"));
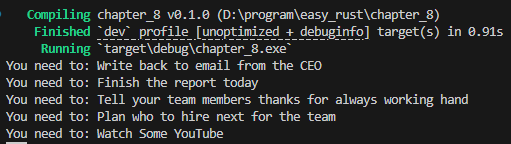
while let Some(job) = jobs.pop() {
println!("You need to: {}", job.1)
}
}
위 코드를 실행하면 아래와 같이 중요한 일부터, 다시 말해 jobs의 첫번째 항목 점수를 기준으로 내림차순으로 정렬됩니다.
2. BinaryHeap의 기본 비교 규칙
BinaryHeap은 내부적으로 T: Ord 트레이트를 요구합니다. 즉, 요소 T 간의 대소 비교(>, <)가 가능해야 하죠.
Rust에서 tuple(예: (i32, &str))도 기본적으로 Ord를 구현하고 있으며, 사전식(lexicographical) 비교를 합니다.
즉, (100, “CEO”)와 (80, “report”)를 비교할 때 → 100 > 80이므로 (100, “CEO”)가 “더 큰” 값으로 간주됩니다.
이 때문에 BinaryHeap은 자동으로 첫 번째 원소(i32) 를 기준으로 최대 힙을 구성합니다.
3. “맨 위(root)”만 정렬되어 있는 이유
BinaryHeap은 완전이진트리(Complete Binary Tree) 구조로 되어 있습니다.
힙은 전체가 정렬되어 있지는 않습니다.
단지 루트 노드(맨 위) 가 항상 가장 큰 값입니다.
나머지는 “힙 속성(heap property)”만 유지합니다: 부모 ≥ 자식
그래서 jobs.pop()을 반복할 때마다
매번 가장 큰 (i32, &str) 튜플이 하나씩 빠집니다.
내부적으로 남은 값들이 재배열되어 다시 최대 힙이 됩니다.
결과적으로, pop()을 반복하면 내림차순 정렬된 순서로 출력되는 것처럼 보이는 거예요.
4. 즉, “항상 정렬되어 있는 게 아니라”
BinaryHeap의 내부 저장순서는 무작위입니다. 하지만 pop()할 때마다 가장 큰 값이 나오는 이유는 “루트만 최대값이 되도록 하는 BinaryHeap 속성” 때문입니다.
5. 정리
개념
의미
내부 저장 순서
무작위 (정렬 아님)
비교 기준
Ord 구현(튜플이면 첫 번째 요소부터 비교)
pop()동작
항상 최대값 반환
출력 결과
내림차순처럼 보임 (사실은 매번 루트 제거 과정 때문)
6. 오름차순 정렬
만약 작은 값부터 꺼내고 싶다면, 즉 “최소 힙(min-heap)”을 원한다면 이렇게 하면 됩니다:
use std::cmp::Reverse;
use std::collections::BinaryHeap;
fn main() {
let mut jobs = BinaryHeap::new();
jobs.push(Reverse((100, "CEO")));
jobs.push(Reverse((80, "Report")));
jobs.push(Reverse((5, "YouTube")));
while let Some(Reverse(job)) = jobs.pop() {
println!("You need to: {}", job.1);
}
}
이렇게 하면 작은 i32부터 오름차순으로 출력됩니다.
요약하자면 👇
BinaryHeap은 내부가 정렬된 컬렉션이 아니라, 루트에만 최대값을 유지하는 자료구조이고, (i32, &str) 튜플은 기본적으로 첫 번째 값으로 비교되기 때문에, pop()을 반복하면 결과적으로 i32 기준 내림차순 출력처럼 보입니다.
use aggregator::summarize;
fn main() {
let text = "Rust makes systems programming fun and safe!";
let summary = summarize(text);
println!("{}", summary);
}
7. Build and run
From the workspace root:
cargo run -p aggregator_app
Output:
Summary: Rust makes systems programming fun and safe!
✅ Now you have:
aggregator → library crate
aggregator_app → binary crate
managed together in one workspace.
Ⅱ. How to Test the Library
Let’s extend the workspace so you can test your aggregator library while also running the app. There are two ways to test library, one is adding tests inside the library and the other is adding separate integration tests in a tests/ directory
1. Add tests inside the library
Edit aggregator/src/lib.rs:
/// Summarize a given text by prefixing it.
pub fn summarize(text: &str) -> String {
format!("Summary: {}", text)
}
// Unit tests go in a special `tests` module.
#[cfg(test)]
mod tests {
// Bring outer functions into scope
use super::*;
#[test]
fn test_summarize_simple() {
let text = "Hello Rust";
let result = summarize(text);
assert_eq!(result, "Summary: Hello Rust");
}
#[test]
fn test_summarize_empty() {
let text = "";
let result = summarize(text);
assert_eq!(result, "Summary: ");
}
}
2. Run the tests
From the workspace root:
cargo test -p aggregator
Output (example):
running 2 tests
test tests::test_summarize_simple ... ok
test tests::test_summarize_empty ... ok
test result: ok. 2 passed; 0 failed
3. Run the app
From the same root:
cargo run -p aggregator_app
Output:
Summary: Rust makes systems programming fun and safe!
4. (Optional) Integration tests
You can also add separate integration tests in a tests/ directory inside the aggregator crate:
use aggregator::summarize;
#[test]
fn integration_summary() {
let text = "Integration testing is easy!";
let result = summarize(text);
assert_eq!(result, "Summary: Integration testing is easy!");
}
Run all tests in the workspace:
cargo test
✅ Now you have:
Unit tests inside src/lib.rs
Integration tests in tests/
Ability to run tests and app from the same workspace.
Mut는 “변수의 값을 바꿀 수 있다(mutable)”는 의미이고, Shadowing은 “같은 변수명을 사용해서 이전의 변수를 가리는” 기능입니다. Shadowing을 통해 Mut의 기능을 대체할 수도 있고, 둘 다 사용하지 않는다면 변수명을 여러 개 사용해야 하는 번거로움이 있습니다.
1. Mut를 사용한 경우
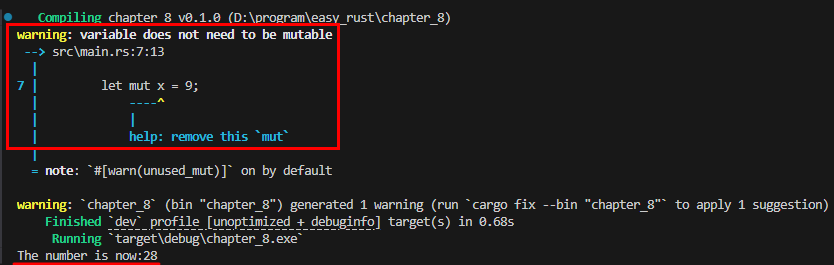
아래 예시는 x를 mutable(가변) 변수로 선언한 다음 => let mut x = 9;
x의 값을 바꿔가면서 원하는 값인 final_number를 출력하는 코드입니다. => x = times_two(x); => x = x + y; 이 때 반환값은 x라고 ;없이 씁니다.
fn times_two(number: i32) -> i32 {
number * 2
}
fn main() {
let final_number = {
let y = 10;
let mut x = 9;
x = times_two(x);
x = x + y;
x
};
println!("The number is now:{}", final_number);
}
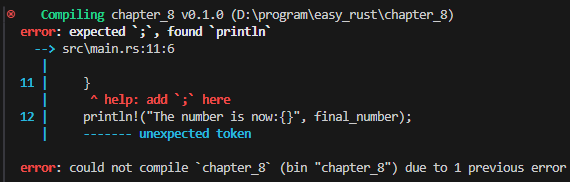
그러나, let final_number가 끝나는 지점에는 let 문이므로 ;을 반드시 붙여야 합니다. 안 붙이면 아래와 같이 ;을 기대했는데, println이 발견됐다는 에러가 표시됩니다.
Rust의 특이한 점이 불변(immutable)이 변수의 기본 상태이고, 변수의 값을 바꿀 수 있게 하려면 mut를 붙여야 한다는 점입니다.
※ 함수 구문
fn times_two(number: i32) -> i32 {
number * 2
}
Rust에서 함수를 선언할 때는 fn을 사용하고 그 다음에 함수명을 붙이는 것은 다른 언어와 같습니다.
그 다음 괄호 안에 인수명을 입력하는데, 여기서는 number이고,
반드시 인수의 타입을 입력해야 하는데, : 다음에 i32 식으로 “32비트 부호 있는 정수” 타입이라고 명시합니다.
이것이 변수의 경우 추론(inference)이 돼서 타입을 반드시 기재해야 할 필요가 없는 것과 다른 점입니다. 변수의 경우 정수는 i32, 실수는 f64가 기본형입니다.
그리고, 반환 값이 있으면 반환 값의 형식도 입력해야 하는데, -> 다음에 i32식으로 입력합니다.
따라서, 반환값이 없으면 ‘-> 반환 값 형식’을 입력하지 않습니다.
그리고, 중괄호 안에 함수의 내용을 기록하고, 반환값을 마지막에 입력하는데, 여기서는 반환값이 number * 2로 인수에 2를 곱한 값을 반환하는 것인데, 마지막에 ;을 붙이지 않는 것도 중요한 점의 하나입니다.
2. Shadowing을 사용한 경우
Shadowing은 “그림자처럼 따라 다님”이란 의미이므로, 여기서는 원래 있던 x 변수를 가리는 역할을 합니다.
Shadowing을 이용하게 되면 x = 을 let x =이라고 쓰고, 처음 변수 선언할 때 mut 없이 let x = 9;이라고 씁니다.
fn times_two(number: i32) -> i32 {
number * 2
}
fn main() {
let final_number = {
let y = 10;
let x = 9;
let x = times_two(x);
let x = x + y;
x
};
println!("The number is now:{}", final_number);
}
만약 let mut x = 9;라고 mut를 붙여도 결과는 같지만, ‘변수가 mutable일 필요가 없다”는 경고와 mut를 제거하라는 도움말이 표시됩니다.
3. shadowing과 mut를 사용하지 않은 경우
fn times_two(number: i32) -> i32 {
number * 2
}
fn main() {
let final_number = {
let y = 10;
let x = 9;
let twice_x = times_two(x);
let twice_x_and_y = twice_x + y;
twice_x_and_y
};
println!("The number is now:{}", final_number);
}
1과 2 예제에서는 변수명으로 x 하나만을 사용했는데,
이번 예제 3에서는 x, twice_x, twice_x_and_y라는 변수 3개를 사용해야 해서 매우 번거롭습니다.
블로그나 티스토리를 쓸 때는 당연히 코드 복사 기능이 있어 불편하지 않았는데, WordPress로 바꾸니 복사 아이콘도 없고, Ctrl + A키를 누르면 화면 전체가 선택돼서, 찾아보니 Copy Anything to Clipboard(한글명 클립보드에 복사)란 플러그인이 있습니다.
1. Copy Anything to Clipboard
가. 플러그인 추가
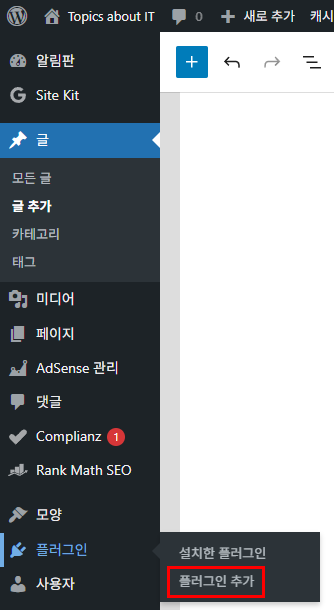
알림판에서 플러그인 > 플러그인 추가를 클릭하고
플러그인 검색 란에 ‘copy anything’이라고 입력하면 한글로 ‘클립보드에 무엇이든 복사하기’로 표시되고, 왼쪽 아이콘 안에 ‘Copy Anything to Clipboard’가 표시됩니다.
지금은 오른쪽 버튼명이 설치가 되고 활성화돼서 ‘활성’이라고 되어 있는데, 설치가 안되어 있다면 오른쪽 플러그인 처럼 ‘지금 설치’라고 되어 있을 것이므로 ‘지금 설치’ 버튼을 눌러 설치합니다.
나. 설정 – 실패 => ‘다. 설정 – 성공’으로 건너뛰어도 됩니다.
플러그인 설치를 하면 아래와 같이 설정 화면이 나옵니다.
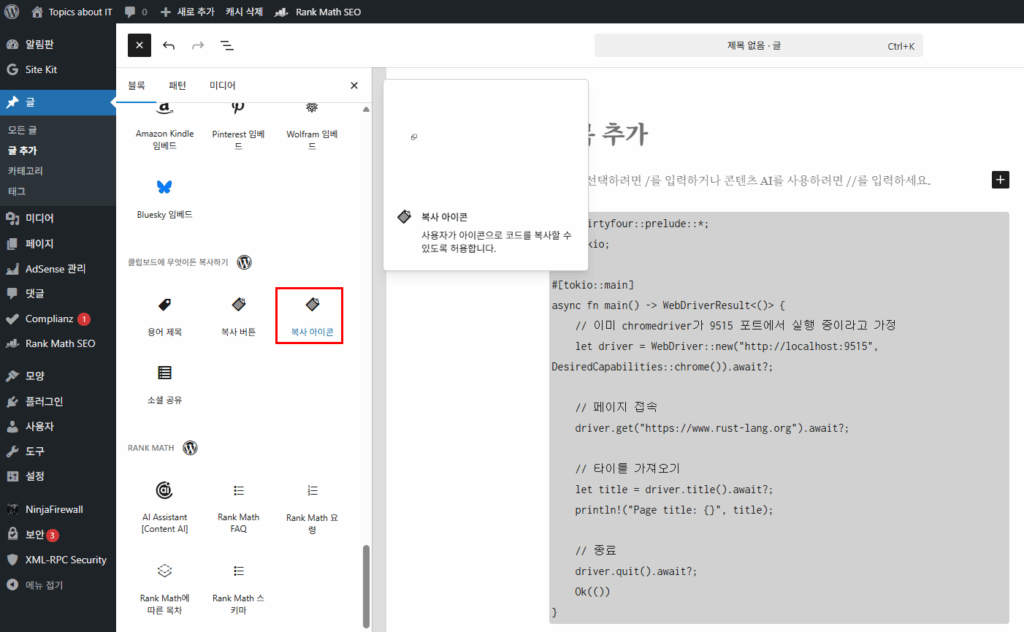
처음에는 뭔지 모르고 그냥 글쓰기로 넘어가서 글을 작성하고,
왼쪽 위 블록 삽입기를 누르고, 맨 아래로 내려가서 ‘클립보드에 무엇이든 복사하기’ 그룹의 ‘복사 아이콘’을 눌러 코드 위에 ‘복사 아이콘’을 추가한 후
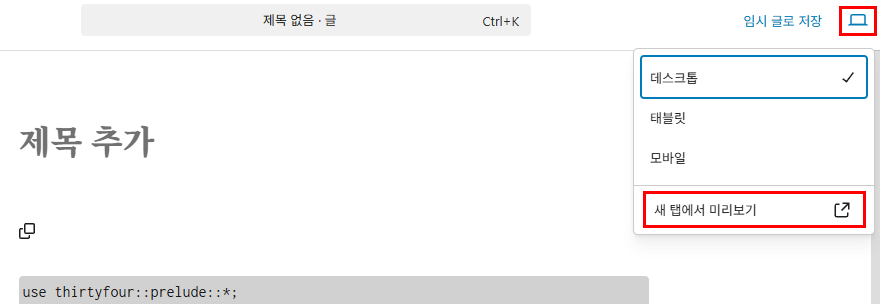
보기 > 새 탭에서 미리 보기를 눌러
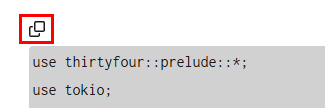
글 위의 복사 아이콘을 누르면
‘Copied’라고는 표시되는데, 메모장에 붙여 넣기를 하면
아무 것도 붙여지지 않습니다.
다. 설정 – 성공
(1) 설정
‘클립보드에 무엇이든 복사하기’ 플러그인을 설정하기 위해
알림판 > 설정 > ‘클립보드에 복사’를 누른 다음
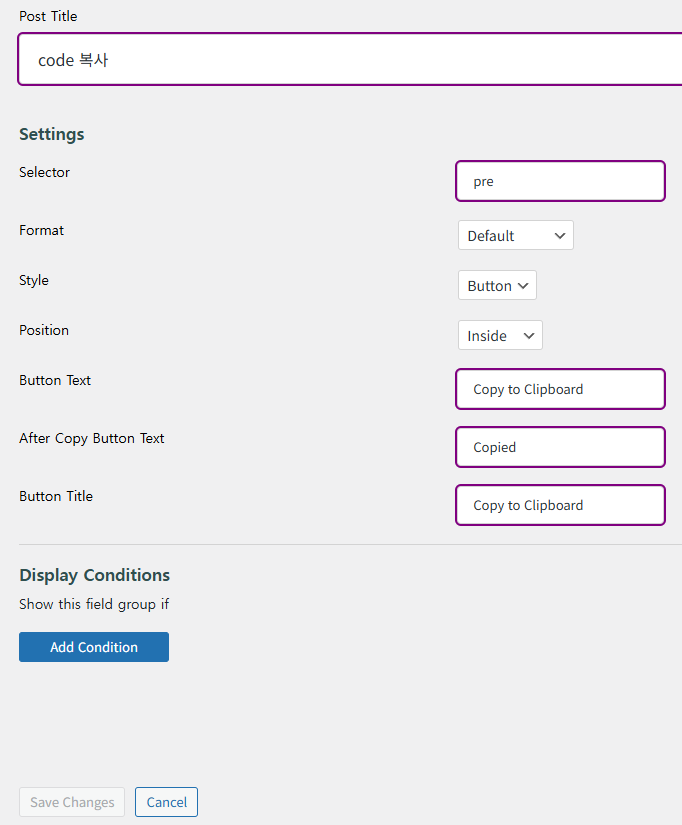
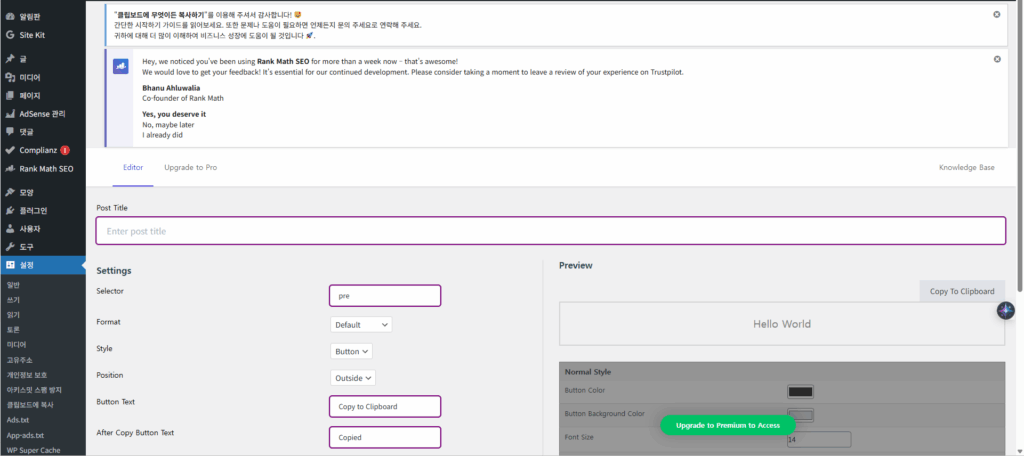
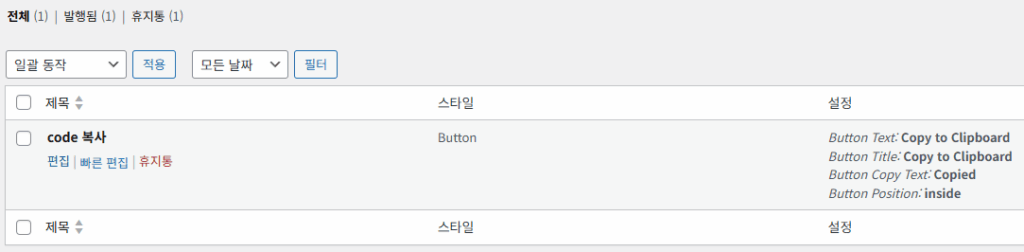
설정을 하는데, 이미 설정이 되어 있으므로, ‘code 복사’ 아래의 편집을 눌러보겠습니다.
그러면 아래와 설정된 내용이 나오는데,
Post Title은 ‘code 복사'(각자 알맞게 설정)이고,
설정(Settings)의 의미는 pre 태그(Selector)가 있으면
Default 형식(글 복사)으로 복사하는데,
모양은 아이콘이 아닌 버튼 모양이고,
버튼의 설명문은 Copy to Clipboard, Copied 등입니다.
설정을 다 했으면 아래 Save Changes 버튼을 눌러 저장합니다. 위에서는 Save Changes가 비활성화되어 있었는데, 설정을 바꾸면 활성화됩니다.
(2) Style – 아이콘과 버튼
버튼 모양이 아닌 아이콘 모양으로 하면
코드 블록의 배경색이 회색인 경우 인지가 잘 안되어
버튼 모양으로 하는 것이 구분이 잘됩니다.
(3) Format – Default, Google Docs, Email
참고로 Format은 Default, Google Docs, Email 형식이 있습니다.
(4) 적용 결과
이제 작성된 글을 보면 코드뿐만 아니라 정형화된 형식으로 작성된 부분에도 ‘Copy To Clipboard’가 윗 부분에 추가된 것을 알 수 있고,
이미 작성된 글 전체에 일괄적으로 적용된 것을 알 수 있습니다.
3. 상세한 설명 사이트
코드 말고, 다른 설정을 하고 싶으면 아래 사이트의 ‘continue reading’를 눌러서 읽어보기 바랍니다.